首先,其实这玩意并不算是完全的破解,因为它还需要人工录入的过程,而不是机器自动识别。如果是机器自动识别的话,那该是神经网络了吧——后文会给出一个别人写的例子……话说 CoffeeScript 是什么……
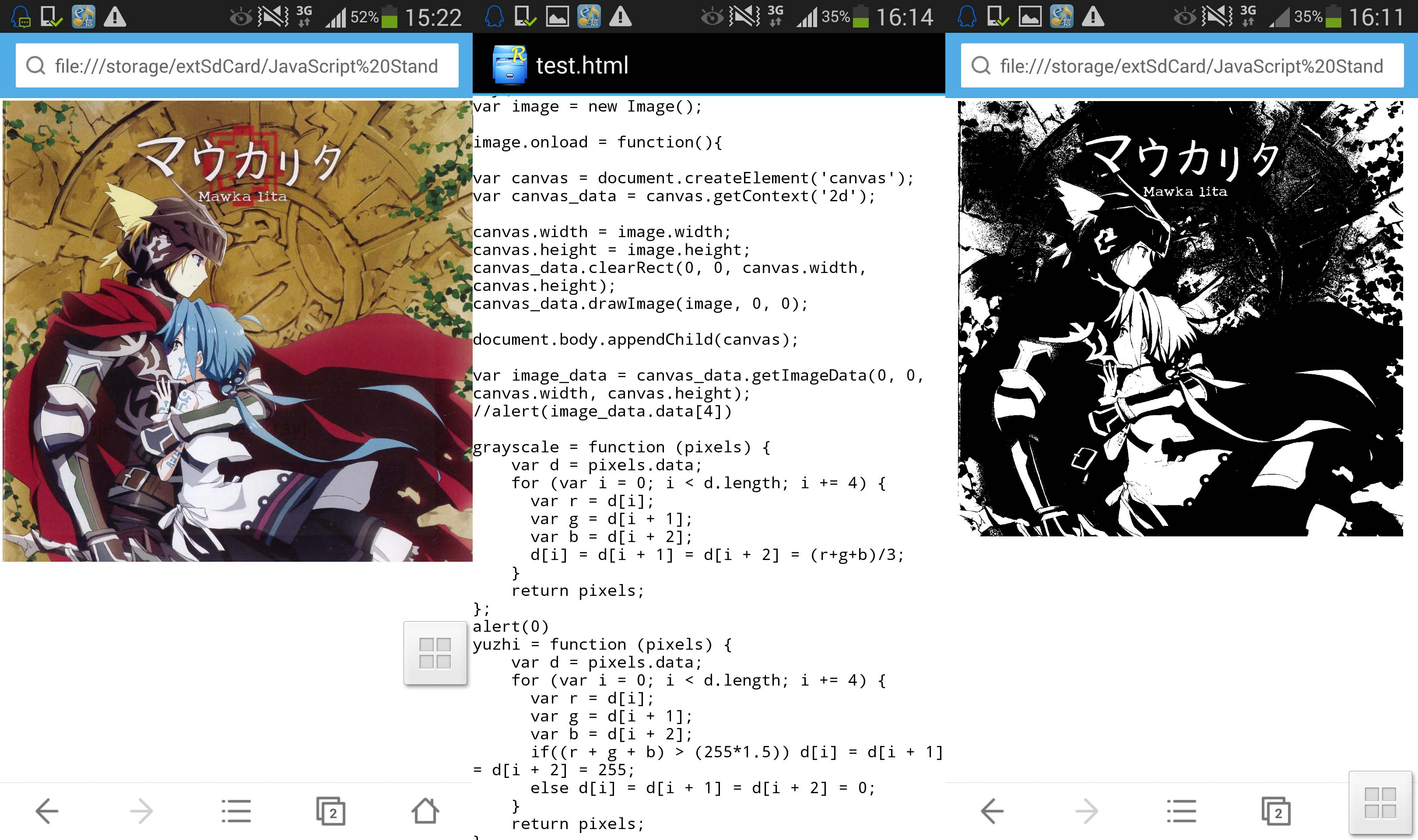
其次,这玩意只能破解非常简单的验证码,也就是那些出现位置固定、没有任何变形和干扰线,甚至颜色差别都不大的验证码,所以像下面这样的验证码还是洗洗睡吧,虽然还是可以识别出验证码的部分,但是识别的话……(canvas 阈值化 by 8q,咳咳,当然 example 也是我们参与的某个玩意的验证码,传说中的自黑)


![7O[W~8}V`YA3{]HTN1Z4A_K](https://ccloli.com/wp-content/uploads/2014/11/7OW8VYA3HTN1Z4A_K-e1416849431254.jpg)
再次,每个网站的验证码风格是不一样的,所以基本很难做到一个程序通杀所有验证码。如果真的有这么想过的话,真的可以洗洗睡了……中文验证码祝你好运……
最后,由于源码是手机码的,所以缩进不统一什么的 _(:3」∠)_……
其实陷入这个坑完全是由于自己的自大 _:3」∠)_ 嘛,具体发生了什么看过之前的文章的同学应该知道,如果不知道的还是最好不要知道了,过去了就过去吧……
首先,让我们看看这个简单的验证码……
可以发现这些验证码组成比较单一,干扰点与验证码颜色区分明显,位置也没有多大变化。
然后我们百度一下,发现用 canvas 破解验证码的还不少,例如 紫云飞大神的这篇文章 与上图基本符合,而国外也有类似的破解某网盘的验证码的脚本,解析原理的文章 思路也是类似的。
接下来,我们先来简单了解一下这里用到的 canvas 的几个用法……其实我了解这玩意是看 阮一峰的 JavaScript 标准参考教程里的 canvas 一节 才知道的,感兴趣可以看看,看完大概十分钟的样子。
首先我们需要将图片插入页面或者 new Image() 并绑定 onload 事件,然后我们需要一个画布,创建一个 canvas 并获取 context,然后进行初始化。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
var image = new Image(); image.onload = function(){ var canvas = document.createElement('canvas'); var canvas_data = canvas.getContext('2d'); // 获取 context canvas.width = image.width; // 设置 canvas 的宽高为图像的大小,据说 css 可能会导致 canvas 拉伸,所以直接设置 canvas 的 width 与 height 属性 canvas.height = image.height; canvas_data.clearRect(0, 0, canvas.width, canvas.height); // 清除内容,四个值对应坐标和清除区域的宽高,感觉在这里似乎没用 canvas_data.drawImage(image, 0, 0); // 将图片载入 canvas,后两个值为坐标 document.body.appendChild(canvas); ...... } image.src = "image.jpg"; |
这样在页面内你就会看见一张绘制了图片的 canvas 了。
接下来是尝试阈值化,首先我们需要获取 canvas 内的图像数据,可以用 getImageData 方法载入这些数据,返回的是一个伪数组,每四个值对应 canvas 对应像素点的 rgba 值。所以我们可以根据此,用合适的计算方法将其转换为一张只有黑色和白色的图片,这便是阈值化。关于阈值的定义请百度一下,这里由于没有百度所以简单粗暴地判断了一下 rgb 之和。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
var image_data = canvas_data.getImageData(0, 0, canvas.width, canvas.height); // 取 image data var yuzhi = function (pixels) { var d = pixels.data; for (var i = 0; i < d.length; i += 4) { // 每四个值对应一个像素点的 r、g、b、a var r = d[i]; var g = d[i + 1]; var b = d[i + 2]; if((r + g + b) > (255*1.5)) d[i] = d[i + 1] = d[i + 2] = 255; // rgb 之和大于 1.5*255 则将其改为白色 else d[i] = d[i + 1] = d[i + 2] = 0; // 否则为黑色,注意这不是标准的阈值运算方法 } return pixels; } yuzhi(image_data); canvas_data.putImageData(image_data, 0, 0); |
这样我们便得到了一张黑白图片,演示效果如下:
嗯,接下来实战演示,通过绘制矩形一步步确定验证码的位置。这是获取图片位置的效果,为了确定验证码位置,我们使用了 fillRect 方法绘制矩形:
![]()
然后用上面的代码取得每个字符对应的区域的 image data,并转换为一组只有 0 和 1 的字符串,手动录入文字并保存。当时测试的源码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
var image = document.querySelector("img"); var keys = JSON.parse(localStorage.getItem('keys'))||{}; var canvas = document.createElement('canvas'); var canvas_data = canvas.getContext('2d'); canvas.width = image.width; canvas.height = image.height; canvas_data.clearRect(0, 0, canvas.width, canvas.height); canvas_data.drawImage(image, 0, 0); document.body.appendChild(canvas); var fetch_text = function(p1, p2, p3, p4){ var image_data = canvas_data.getImageData(p1, p2, p3, p4); //alert(image_data.data[4]) yuzhi = function (pixels) { var d = pixels.data; var data = ""; // 存储字符串的变量 for (var i = 0; i < d.length; i += 4) { var r = d[i]; var g = d[i + 1]; var b = d[i + 2]; if((r + g + b) > (255*2)) { d[i] = d[i + 1] = d[i + 2] = 255; data += '0'; } else { d[i] = d[i + 1] = d[i + 2] = 0; data += '1'; } } canvas_data.putImageData(pixels, p1, p2); var key = prompt(data, ''); // 手动录入验证码文字 if(key!='') keys[key] = data; return pixels; } yuzhi(image_data); } fetch_text(3, 5, 16, 20); fetch_text(19, 5, 16, 20); fetch_text(35, 5, 16, 20); fetch_text(51, 5, 16, 20); localStorage.setItem('keys',JSON.stringify(keys)); window.location.href=window.location.href; // 获取新图片 |
最后得到了这样一堆玩意……

接下来把代码改改,就可以用这些数据识别验证码了,这样只要字符串对应的文本相同就可以匹配到对应的字符。可是,准确率不高啊,有些字识别不出来……
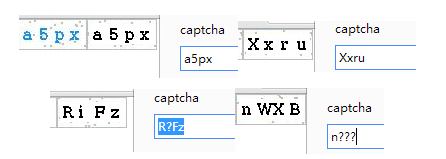
(于是写到两点半才写到这还没写完 _(:3」∠)_ 本子已经强制关机了……)
刚开始估计有可能是字符有些许移位,所以尝试统计每个字对应的字符串中 1 的个数,不过看来我想太多了,因为 1 相同的字符数略多,例如 1 出现了 55 次的就有 4 个字符对应……
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
1: 36 2: 47 3: 48 4: 57 5: 55 6: 56 7: 36 8: 61 9: 55 D: 62 A: 58 d: 55 a: 49 b: 50 L: 46 M: 77 I: 32 m: 70 R: 65 U: 59 s: 40 p: 54 B: 80 y: 45 v: 38 X: 61 C: 48 n: 47 H: 76 Z: 64 G: 60 J: 43 r: 34 K: 65 W: 76 t: 33 w: 56 e: 43 T: 52 q: 57 j: 37 i: 28 Y: 45 F: 66 k: 55 f: 44 g: 60 c: 37 h: 51 z: 46 x: 48 Q: 61 S: 54 P: 53 N: 75 u: 47 V: 49 |
所以这个方法得到的文本并不准确,于是有想将选区进行适当移位,直至字符串匹配……
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
if(yuzhi(image_data)!=true){ var image_data = canvas_data.getImageData((p1-1), p2, p3, p4); if(yuzhi(image_data)!=true){ var image_data = canvas_data.getImageData((p1+1), p2, p3, p4); if(yuzhi(image_data)!=true){ var image_data = canvas_data.getImageData((p1-2), p2, p3, p4); if(yuzhi(image_data)!=true){ var image_data = canvas_data.getImageData((p1+2), p2, p3, p4); if(yuzhi(image_data)!=true) captcha+='?'; } } } } |
咳咳,当然还是惨不忍睹……看来这算法还是不科学啊……再尝试字符串一个一个文字匹配……呵呵了 orz……
仔细思考后,考虑到有可能是生成图片的噪点覆盖了部分字符,导致无法完全匹配。所以我们尝试将生成的字符串分割成好几段,对每一段字符串进行匹配,取匹配次数最多的字符,最后终于做到了几乎 100% 匹配。

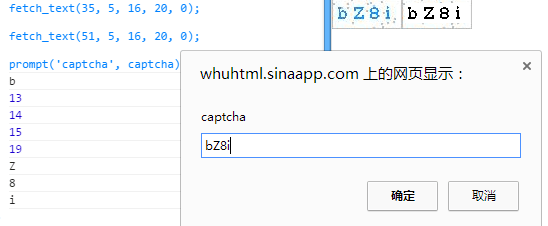
咳咳,由于完成之后没几分钟验证码机制就改了,所以没法做更多的测试了,不过在测试的验证码中都完全识别了出来。
最后附识别源码,只是前面的源码改了一下而已。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 |
var image = document.querySelector("img"); var keys = JSON.parse(localStorage.getItem('keys')); var captcha=""; var canvas = document.createElement('canvas'); var canvas_data = canvas.getContext('2d'); canvas.width = image.width; canvas.height = image.height; canvas_data.clearRect(0, 0, canvas.width, canvas.height); canvas_data.drawImage(image, 0, 0); document.body.appendChild(canvas); var fetch_text = function(p1, p2, p3, p4, c){ var image_data = canvas_data.getImageData(p1, p2, p3, p4); //alert(image_data.data[4]) yuzhi = function (pixels) { var d = pixels.data; var data = ""; for (var i = 0; i < d.length; i += 4) { var r = d[i]; var g = d[i + 1]; var b = d[i + 2]; if((r + g + b) > (255*2)) { d[i] = d[i + 1] = d[i + 2] = 255; data += '0'; } else { d[i] = d[i + 1] = d[i + 2] = 0; data += '1'; } } canvas_data.putImageData(pixels, p1, p2); var pkey='?'; var pkey_value=0; var passed=0; for(var i in keys) { if(keys[i]==data) { // 首先检查是否字符串完全匹配 pkey=i; pkey_value=1; passed = 1; break; } /*else { // 文字逐一匹配,正确率呵呵 var split_key=keys[i].split(''); var split_data=data.split(''); var count=0; for(var j=0;j<split_key.length;j++){ if(split_key[j]==split_data[i])++count; } console.log(count / split_key.length) if((count / split_key.length)>=pkey_value){ pkey=i; pkey_value=count / split_key.length; } }*/ } if(passed == 0){ var match_count = 0; for(var i in keys) { //if(data.match(/1/gi).length==keys[i].match(/1/gi).length){ var data_groups = data.match(/.{16}/gi); // 每 16 个字符(矩形的宽为 16px)进行一次分割 var key_groups = keys[i].match(/.{16}/gi); var _match_count = 0; for(var j=0; j<20;j++){ if((data_groups[j].match(/0/gi).length) == (key_groups[j].match(/0/gi).length)){ // 如果该区段字符串相同则 ++_match_count ++_match_count; } } if(_match_count>match_count){ // 取匹配数最多的字符串 match_count=_match_count; console.log(match_count) pkey=i; } //break; //} //break; } } console.log(pkey); captcha+=pkey; //if(pkey_value==1)return true; } yuzhi(image_data) } fetch_text(3, 5, 16, 20, 0); fetch_text(19, 5, 16, 20, 0); fetch_text(35, 5, 16, 20, 0); fetch_text(51, 5, 16, 20, 0); prompt('captcha', captcha); |
附录:
1. 使用神经网络破解验证码的脚本 http://userscripts-mirror.org/scripts/show/183059
2. 另一个类似的例子 http://www.cnblogs.com/gdut-link/archive/2013/01/25/2876697.html
3. 刚刚 Google 一下似乎还看到了破解拖动图片验证码的玩意,感兴趣可以看看 http://my.oschina.net/u/237940/blog/337194
哇 ,好厉害。
_(:зゝ∠)_手机代码菊苣
rgb不算标准差直接加和真的没问题吗……
当时是不知道什么是阈值所以简单粗暴的 rgb 相加 _(:3」∠)_ 实现功能就好,算法什么的……
原来用的是二值化的处理方法,噪点处理的不错
前三张图不是我做的 _(:3」∠)_
ヾ(:3ノシヾ)ノシ不愧是cc菊苣QAAQ
不错,收藏以后学习学习~
CoffeeScript 是我大Ruby党开发时候的利器. 用近乎Ruby/Python的语法而不用写原生的js , 简直爽!
菊苣!
juju!
赞一个
其实我也有挺完整的思路不过不打算做这样的东西。。
不愧是CC菊苣
我想到众复旦魔们破解选课验证码的故事了