最近教务系统的验证码又切换回了旧版的随机位置 + 斜体了,这学期弄的验证码识别也算是废了。这学期采用的新验证码虽然基本每个字符都有粘连,但是由于文本的位置基本是固定的,而且也没有过多的旋转,所以简单地取字模也是可以的(虽然识别率还是非常糟糕啦 _(:3)。现在换回了旧版后反而有些麻烦了,毕竟字符的旋转还是挺难处理的。由于自己用最好的编程语言写了个简单的爬虫,所以顺带试试看做验证码识别吧。
目前网上比较有名的 OCR 应该算是 Tesseract 了吧,Python 端的验证码识别软件 pytesser 就是基于 Tesseract 的。再加上前两年的时候 OpenShift 推出了 Build-It-Yourself 的玩意,就是一个应用 gear 里不仅可以安装 OpenShift 已经提供的 cartridge,用户还可以自己编写一个一键配置脚本,让 OpenShift 导入并安装。于是便考虑在 OpenShift 的一个应用上安装个 Tesseract,至于是不是违反 TOS 什么的再说啦先玩玩再说(x
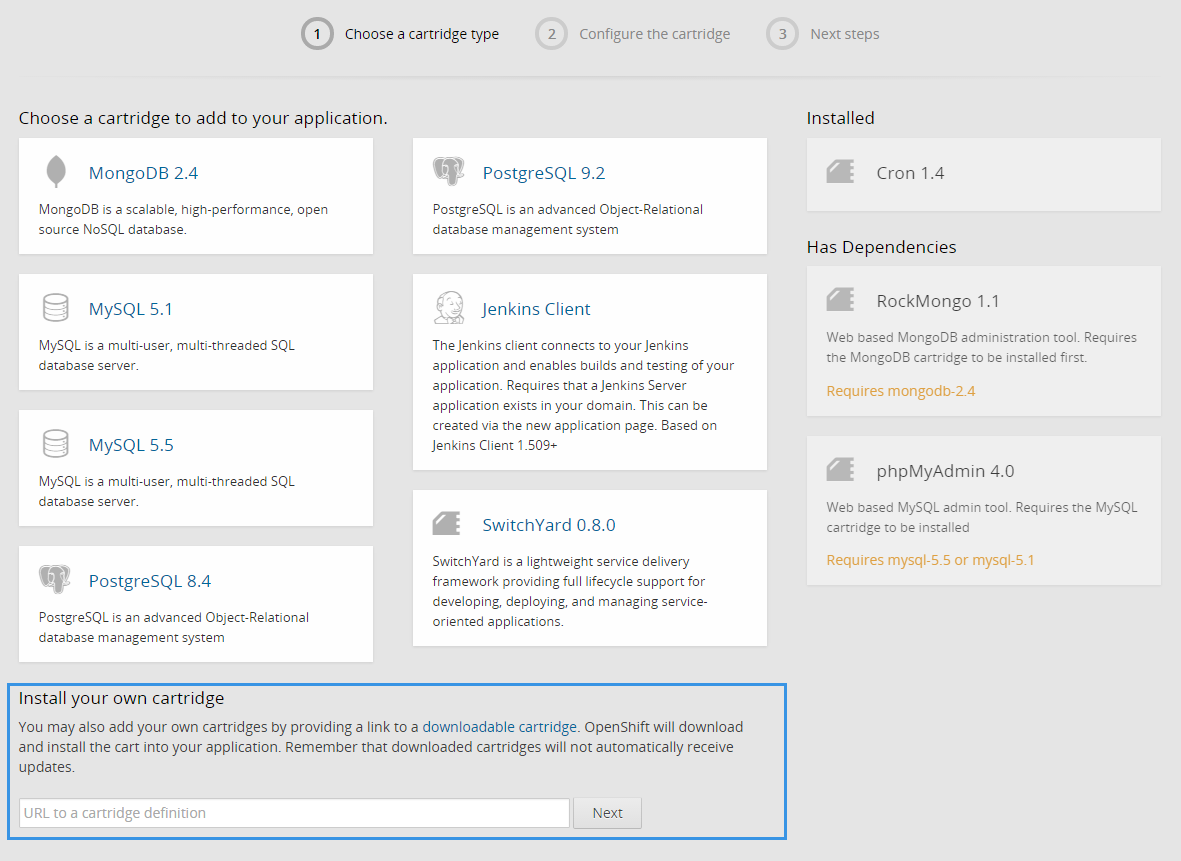
借助于 GitHub 我们发现已经有大神编写了一键配置脚本了,所以难度比预想的简单很多。在测试了几个代码后我们发现了直接可用的版本,虽然配置清单有个小 bug,不过 fork 后修改一下就能用了(第二个是 fork 并修改后的版本)。
lucasvillar / openshift-tesseract-build-cartridge
这个仓库不存在或已被移除。
https://github.com/lucasvillar/openshift-tesseract-build-cartridge
ccloli / openshift-tesseract-build-cartridge
这个仓库没有描述或主页。
https://github.com/ccloli/openshift-tesseract-build-cartridge
接下来找到 metadata/manifest.yml 文件,把它贴入上图的文本框中,并点击 Next 按钮,再点击 Add Cartridge 按钮就行了,安装无误且完成后会在 gear 内显示。
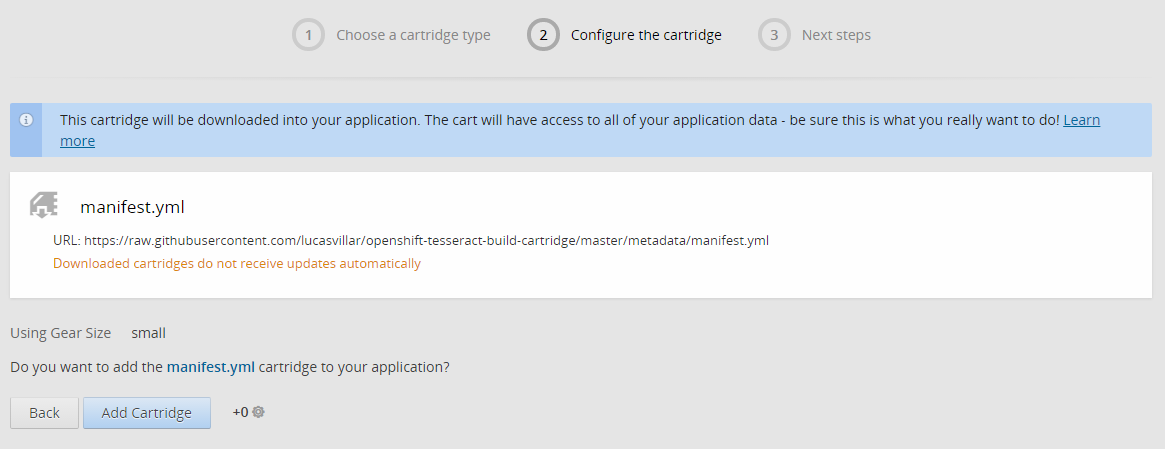
由于服务器的语言环境是最好的编程语言,所以又找到了个 Tesseract OCR for PHP,把它解压到 app-root/runtime/repo/ 下的一个目录里,用于调用。
thiagoalessio / tesseract-ocr-for-php
A wrapper to work with Tesseract OCR inside PHP.
接下来用 ssh 登录到应用内,找到 /tesseract-build/bin/compile,然后执行它,如果运气不错的话应该能正常使用……
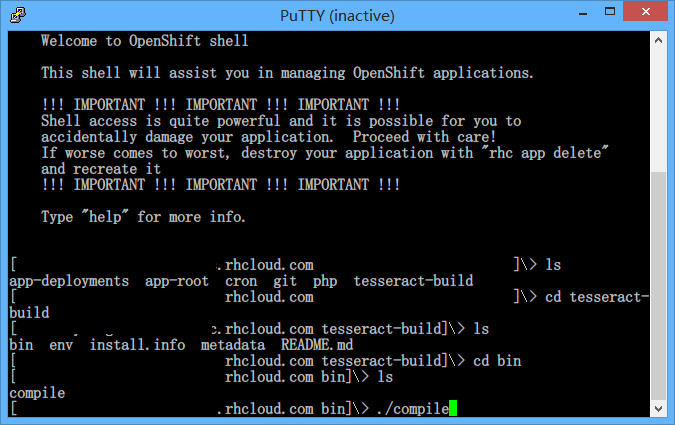
才怪 _(:3 cat 一下,发现第二行就写着 # usage: bin/compile ……大哥你不传入路径我安装在哪啊 _(:3 好吧我当时还真犯了这个错误,然后去看了作者的 GitHub,发现还提供了另一个已经编译好的版本,同样添加到 gear 里,不过发现并不能被调用,最后发现原来 Tesseract OCR for PHP 只支持 v3.03+ 的 Tesseract,而编译的版本是 3.02.02。于是乖乖地用即时编译的版本吧,然后在修改时才发现原来是没有传入 build-dir _(:3
不过即便加上了编译路径咱也没有这么幸运 _(:3 从输出上看前面的 libtool 和 leptonica 编译还挺顺利的,但是后面的 tesseract 炸了,压缩包解压后提醒没有 libtool 之类的玩意,可是我刚刚明明编译了啊 _(:3 于是在 ssh 里手动输入了几行 export 才解决问题,顺带把下载路径从 Google Code 换成了 GitHub(因为 Google Code 没有新版本)。
|
1 2 3 4 5 6 |
# /var/lib/openshift/$OPENSHIFT_GEAR_UUID/tesseract/ 为传入的 build-dir # libtool export PATH=$PATH:/var/lib/openshift/$OPENSHIFT_GEAR_UUID/tesseract/libtool/bin # leptonica export LIBLEPT_HEADERSDIR=/var/lib/openshift/$OPENSHIFT_GEAR_UUID/tesseract/leptonica/include export PATH=$PATH:/var/lib/openshift/$OPENSHIFT_GEAR_UUID/tesseract/leptonica/bin |
接下来再 compile 一次,结果发现这回变成了文件路径不正确。这 TM 就很尴尬了,难道是权限没给对?作死设置成了 777 也还是有问题啊,而且默认的 755 应该也没问题啊……纠结了很久后试着 ls /tmp/,结果发现原来是从 GitHub 下载的压缩包里的文件夹名字和默认从 Google Code 下载的文件夹名字不一样……一口老血……
修改好后再 compile 一次,结果编译到一半还断开连接了……妈蛋我还是连着 ss 的啊,这样还能被墙,简直了 = =
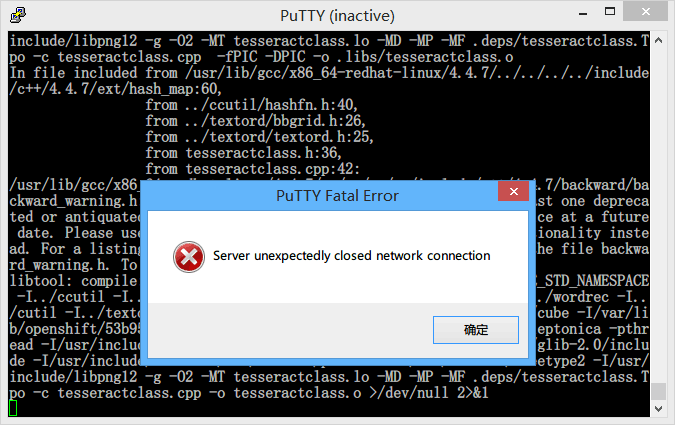
再编译一次,终于过了 =w=
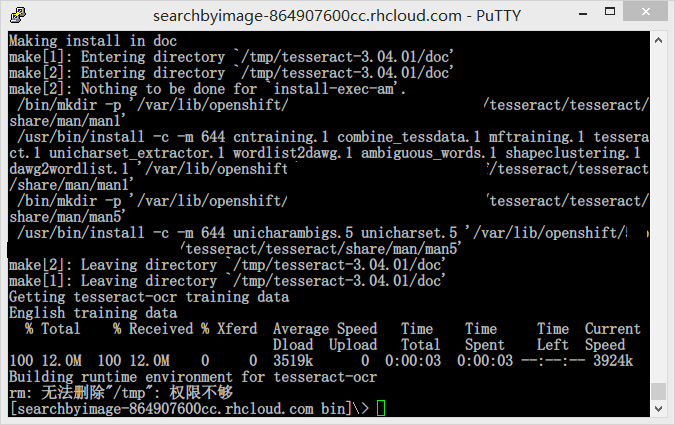
接下来在 TesseractOCR.php 里修改一些参数,将 $executable 指定为最终的 tesseract 路径。
|
1 2 3 4 5 6 7 |
/** * Path to tesseract executable. * Default value assumes it is present in the $PATH. * * @var string */ private $executable = $OPENSHIFT_HOMEDIR . 'tesseract/tesseract/bin/tesseract'; |
接下来就可以调用了~~~
|
1 2 3 4 5 6 7 |
<?php require 'TesseractOCR.php'; echo (new TesseractOCR('GenImg.png')) ->whitelist(range('A', 'Z'),range('a', 'z'), range(0, 9)) ->run(); |
虽然只是使用了 Tesseract 默认的英文库,也没有进行过训练,但是在去除噪点后准确率已经比之前用 JavaScript 配合 Canvas 取字模高很多啦~~
![2016-06-17-195322_lim[lossy-quick]](http://ccloli.com/wp-content/uploads/2016/06/2016-06-17-195322_limlossy-quick.png)
另外发现在 GitHub 上其实已经有小伙伴把教务系统验证码的识别做好了,不过直接把他们的识别数据覆盖 Tesseract 的 tessdata 好像没有用,待以后再研究 _(:3