Title image of Streams API by Mozilla Contributors is licensed under CC-BY-SA 2.5.
此文章的略微润色版可前往 知乎、掘金、SegmentFault、专栏 查看
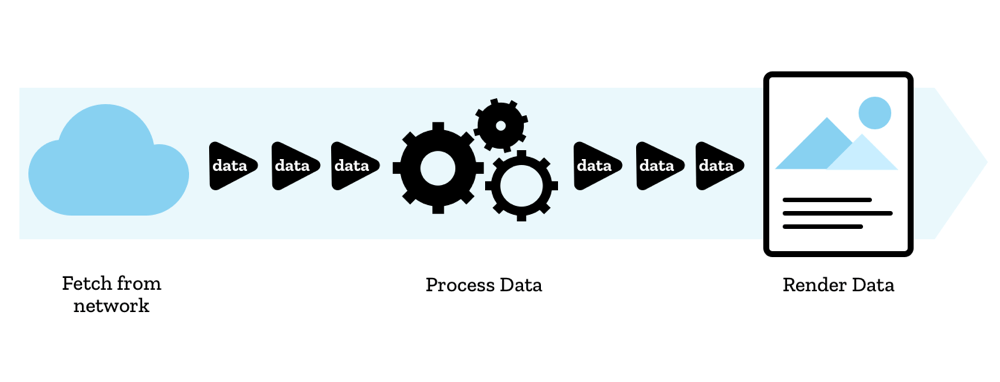
在服务端开发中,流是一个很常见的概念。有了流我们就不再需要等待整个数据获取完毕后才处理数据,而是可以一段一段地拿到数据,在获得数据的同时直接解析数据。这样既可以高效利用 CPU 等资源,还减少了存放整个数据的内存占用。不过在过去,客户端 JavaScript 上都没有流的概念,而随着 Streams API 在各大浏览器上的逐步实现,我们终于可以使用原生的 API 以流的角度来看待数据了,例如从 fetch 请求上可以得到一个网络流。
既然标题是「从 Fetch 到 Streams」,那么首先让我们来看看既熟悉又陌生的 Fetch API。相比较于 XMLHttpRequest,fetch() 的写法简单又直观,只要在发起请求时直接将整个配置项传入就可以了。fetch() 方法接受一个 Request 实例,或者是大家更常使用的方法——传入需要请求的 URL 以及一个可选的初始化配置项对象,然后就可以从 Promise 中取得返回的数据:
|
1 2 3 4 5 6 7 8 9 10 11 |
fetch('https://example.org/foo', { method: 'POST', mode: 'cors', headers: { 'content-type': 'application/json' }, credentials: 'include', redirect: 'follow', body: JSON.stringify({ foo: 'bar' }) }).then(res => res.json()).then(...) |
如果你不喜欢 Promise 的链式调用的话,还可以用 async/await:
|
1 2 3 |
const res = await fetch('https://example.org/foo', { ... }); const data = await req.json(); |
看起来相当的直观,在请求时直接将所有的参数传入 fetch() 方法即可,甚至相较于 XHR 还提供了更多的控制参数,例如是否携带 Cookie、是否需要手动跳转等;取出数据也只需要调用 Response 对象上的方法就能拿到格式化的数据(例如 res.json())。而直接使用 XMLHttpRequest 看起来就没那么方便了,初始化时既有方法的调用又有参数的赋值,看着还挺混乱的:
|
1 2 3 4 5 6 7 8 9 10 11 |
const xhr = new XMLHttpRequest(); xhr.open('POST', 'https://example.org/foo'); xhr.setRequestHeader('Content-Type', 'application/json'); xhr.responseType = 'json'; xhr.withCredentials = true; xhr.addEventListener('load', () => { const data = xhr.response; // ... }); xhr.send(JSON.stringify({ foo: 'bar' })) |
而随着 AbortController 与 AbortSignal 在各大浏览器上完整实现,Fetch API 也能像 XHR 那样中断一个请求了,只是稍微绕了一点。通过创建一个 AbortController 实例,我们就得到了一个可以控制中断的控制器。这个实例的 signal 参数提供了一个 AbortSignal 实例,还提供了一个 abort() 方法用于发送中断信号。我们将 signal 传递进 fetch() 的初始化参数中,就可以在 fetch 请求之外控制请求的中断了:
|
1 2 3 4 5 6 |
const controller = new AbortController(); const { signal } = controller; fetch('/foo', { signal }).then(...); signal.onabort = () => { ... }; controller.abort(); |
只可惜提出这个解决方案并实装的时间还是有点晚,Fetch API 早在 就在 Firefox 上实现,并且最早于 在 Chrome 上实装。而该功能最早也是 Edge 浏览器在 2017 年 4 月实现,Safari 直到 2018 年末才被发现 AbortController 不能中断请求的 bug,最后在 2019 年 3 月的 Safari 12.1 中才正式解决。算下来从 Fetch API 在浏览器上实装开始,到主流现代浏览器全部支持,跨越了整整四年。
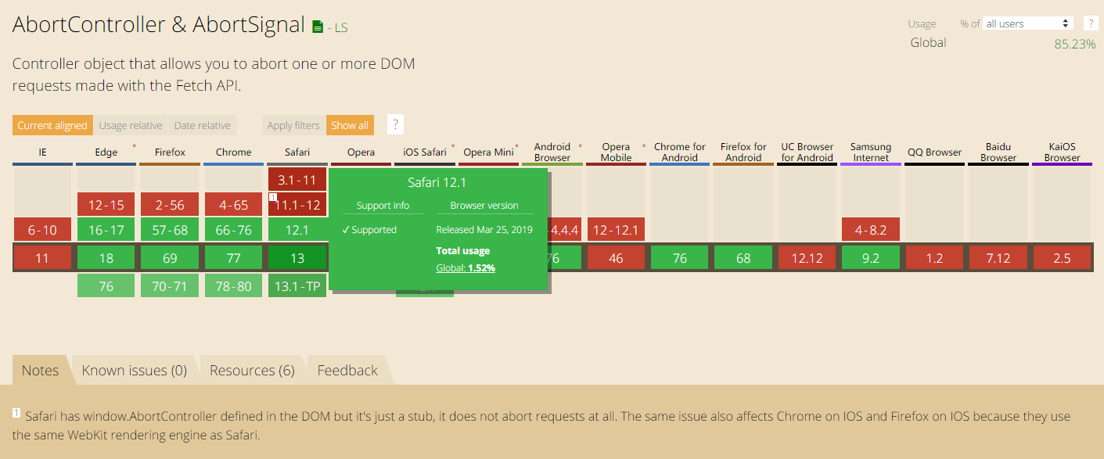
Image of AbortController & AbortSignal Support Table by caniuse.com is licensed under CC-BY 4.0.
晚归晚,但是看起来现在的 Fetch API 已经无所不能了,不过在「真香」之前,我们来考虑一个很常见的场景:浏览器需要异步请求一个比较大的文件,由于可能比较耗时,希望在下载文件时展示文件的下载进度。XHR 提供了很多的事件,其中就包括了传输进度的 onprogress 事件,所以使用 XHR 可以很方便地实现这个功能:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
const xhr = new XMLHttpRequest(); xhr.open('GET', '/foo'); xhr.addEventListener('progress', (event) => { const { lengthComputable, loaded, total } = event; if (lengthComputable) { console.log(`Downloaded ${loaded} of ${total} (${(loaded / total * 100).toFixed(2)}%)`); } else { console.log(`Downloaded ${loaded}`); } }); xhr.send(); |
但是 Fetch API 呢?你打开了 MDN,仔细地看了 fetch() 方法的所有参数,都没有找到类似 progress 这样的参数,毕竟 Fetch API 并没有什么回调事件。难道 Fetch API 就不能实现这么简单的功能吗?这里就要提到和它相关的 Streams API 了——不是 Web Socket,也不是 Media Stream,更不是只能在 Node.js 上使用的 Stream,不过和它很像。
Streams API 能做什么?
对于非 Web 前端的同学来说,流应该是个很常见的概念,它允许我们一段一段地接收与处理数据。相比较于获取整个数据再处理,流不仅不需要占用一大块内存空间来存放整个数据,节省内存占用空间,而且还能实时地对数据进行处理,不需要等待整个数据获取完毕,从而缩短整个操作的耗时。
此外流还有管道的概念,我们可以封装一些类似中间件的中间流,用管道将各个流连接起来,在管道的末端就能拿到处理后的数据。例如,下面的这段 Node.js 代码片段实现了解压 zip 中的文件的功能,只需要从 zip 的中央文件记录表中读取出各个文件在 zip 文件内的起止偏移值,就能将对应的文件解压出来。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
const src = fs.createReadStream(null, { fd, start, end, autoClose: false }); const dest = fs.createWriteStream(outputPath + name); // 从流中直接读取数据 src.on('data', (chunk) => { ... }); // 或者直接将流引向另一个流 if (compressed) { src.pipe(zlib.createInflateRaw()).pipe(dest); } else { src.pipe(dest); } |
其中的 input 是一个可读取的流,output 是一个可写入的流,而 zlib.createInflateRaw() 就是创建了一个既可读取又可写入的流,它在写入端以流的形式接受 Deflate 压缩的数据,在读取端以流的形式输出解压缩后的数据。我们想象一下,如果输入的 zip 文件是一个上 GB 的大文件,使用流的方式就不再需要占用同样大小的上 GB 的内存空间。而且从代码上看,使用流实现的代码逻辑同样简洁和清晰。
很可惜,过去在客户端 JavaScript 上并没有原生的流 API——当然你可以自己封装实现流,比如 JSZip 在 3.0 版本就封装了一个 StreamHelper,但是基本上除了使用这些 stream 库的库以外,没有其它地方能 产生 兼容这个库的流了。没有能产生流的数据源才是大问题,比如想要读取一个文件?过去 FileReader 只能在 onload 事件上拿到整个文件的数据,或者对文件使用 slice() 方法得到 Blob 文件片段,~~目前也没有原生的 FileReaderStream 之类的 API~~。
现在 Streams API 已经在浏览器上逐步实现(或者说,早在 2016 年 Chrome 就开始支持一部分功能了),能用上流处理的 API 想必也会越来越多,而 Streams API 最早的受益者之一就是 Fetch API。


Streams API 赋予了网络请求以片段处理数据的能力,过去我们使用 XMLHttpRequest 获取一个文件时,我们必须等待浏览器下载完整的文件,等待浏览器处理成我们需要的格式,收到所有的数据后才能处理它。现在有了流,我们可以以 TypedArray 片段的形式接收一部分二进制数据,然后直接对数据进行处理,这就有点像是浏览器内部接收并处理数据的逻辑。甚至我们可以将一些操作以流的形式封装,再用管道把多个流连接起来,管道的另一端就是最终处理好的数据。
Fetch API 会在发起请求后得到的 Promise 对象中返回一个 Response 对象,而 Response 对象除了提供 headers、redirect() 等参数和方法外,还实现了 Body 这个 mixin 类,而在 Body 上我们才看到我们常用的那些 res.json()、res.text()、res.arrayBuffer() 等方法。在 Body 上还有一个 body 参数,这个 body 参数就是一个 ReadableStream。
既然本文是从 Fetch API 的角度出发,而如前所述,能产生数据的数据源才是流处理中最重要的一个部分,那么下面我们来重点了解下这个在 Body 中负责提供数据的 ReadableStream。
这篇文章不会讨论流的排队策略(如
highWaterMark),也不会讨论没有浏览器实现的 BYOR reader,感兴趣的同学可以参考相关规范文档
ReadableStream
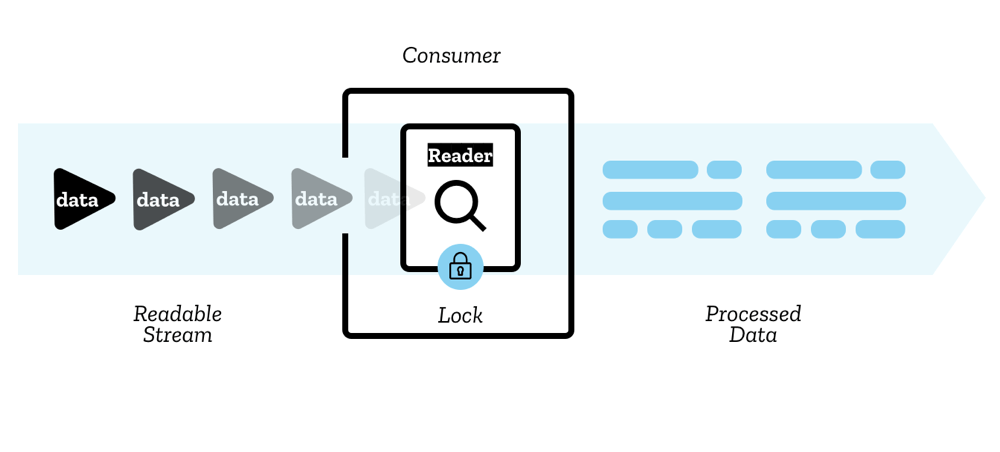
The image of ReadableStream Concept by Mozilla Contributors is licensed under CC-BY-SA 2.5.
下面是一个 ReadableStream 实例上的参数和可以使用的方法,下文我们将会详细介绍它们:
ReadableStream
– locked
– cancel()
– pipeThrough()
– pipeTo()
– tee()
– getReader()
其中直接调用 getReader() 方法会得到一个 ReadableStreamDefaultReader 实例,通过这个实例我们就能读取 ReadableStream 上的数据。
从 ReadableStream 中读取数据
ReadableStreamDefaultReader 实例上提供了如下的方法:
ReadableStreamDefaultReader
– closed
– cancel()
– read()
– releaseLock()
假设我们需要读取一个流中的的数据,可以循环调用 reader 的 read() 方法,它会返回一个 Promise 对象,在 Promise 中返回一个包含 value 参数和 done 参数的对象。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const reader = stream.getReader(); let bytesReceived = 0; const processData = (result) => { // Result objects contain two properties: // done - true if the stream has already given all its data. // value - some data. Always undefined when done is true. if (result.done) { console.log(`complete, total size: ${bytesReceived}`); return; } // value for fetch streams is a Uint8Array const value = result.value; const length = value.length; console.log(`got ${length} bytes data:`, value); bytesReceived += length; // Read some more, and call this function again return reader.read().then(processData); }; reader.read().then(processData); |
其中 result.value 参数为这次读取得到的片段,它是一个 Uint8Array,通过循环调用 reader.read() 方法就能一点点地获取流的整个数据;而 result.done 参数负责表明这个流是否已经读取完毕,当 result.done 为 true 时表明流已经关闭,不会再有新的数据,此时 result.value 的值为 undefined。
现在我们已经知道 Fetch API 返回的 Response 对象可以拿到一个对应的 ReadableStream,以及如何从一个 ReadableStream 中得到数据了。那么回到我们之前的问题,我们可以通过读取 Response 中的流得到目前接收的片段,累加各个 Uint8Array 片段的 length 属性就能得到类似 XHR onprogress 事件的 loaded;通过从 Response 的 headers 中取出 Content-Length 属性就能得到类似 XHR onprogress 事件的 total。于是我们可以写出下面的代码,成功得到下载进度:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
let total = null; let loaded = 0; const logProgress = (reader) => { return reader.read().then(({ value, done }) => { if (done) { console.log('Download completed'); return; } loaded += value.length; if (total === null) { console.log(`Downloaded ${loaded}`); } else { console.log(`Downloaded ${loaded} of ${total} (${(loaded / total * 100).toFixed(2)}%)`); } return logProgress(reader); }); }; fetch('/foo').then((res) => { total = res.headers.get('content-length'); return res.body.getReader(); }).then(logProgress); |
看着好像没问题是吧?问题来了,数据呢?我那么大一个返回数据呢?上面的代码只顾着输出进度了,结果并没有把返回数据传回来。虽然我们可以直接在上面的代码里处理二进制数据片段,可是有时我们还是会偷懒,直接得到完整的数据进行处理(比如一个巨大的 JSON 字符串)。
如果我们希望接收的数据是文本,一种解决方案是拼接得到的 Uint8Array 并返回,然后再使用 TextDecoder 等方法得到解析后的文本:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
let chunk = new Uint8Array(0); const logProcess = (res) => { const reader = res.body.getReader(); const push = ({ value, done }) => { if (done) return chunk; // chunk is an Uint8Array const newChunk = new Uint8Array(chunk.length + value.length); newChunk.set(chunk, 0); newChunk.set(value, chunk.length); chunk = newChunk; // ... return reader.read().then(push); }; return reader.read().then(push); }; fetch('/foo').then(logProgress).then((res) => { const decoder = new TextDecoder('utf-8'); const text = decoder.decode(res); const data = JSON.parse(res); // ... }); |
或者我们可以在读取片段时就解析文本,最终直接返回解析后的整个文本:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
let text = ''; const logProcess = (res) => { const reader = res.body.getReader(); const decoder = new TextDecoder('utf-8'); const push = ({ value, done }) => { if (done) return JSON.parse(text); text += decoder.decode(value, { stream: true }); // ... return reader.read().then(push); }; return reader.read().then(push); }; fetch('/foo').then(logProgress).then((res) => { ... }); |
不过如果你犯了强迫症,一定要像原来那样显示调用 res.json() 之类的方法得到数据,这该怎么办呢?既然 fetch() 方法返回一个 Response 对象,而这个对象的数据已经在 ReadableStream 中读取下载进度时被使用了,那我再造一个 ReadableStream 外面再包一个 Response 对象,问题不就解决了吗?
构造一个 ReadableStream
构造一个 ReadableStream 时可以定义以下方法和参数:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
const stream = new ReadableStream({ start(controller) { // called immediately when the object is constructed controller.desiredSize // the desired size required to fill the queue controller.close() // close the stream controller.enqueue(chunk) // enqueue a given chunk in the stream controller.error(reason) // cause an error to stream }, pull(controller) { // called repeatedly when the stream's internal queue of chunks // is not full, up until it reaches its high water mark }, cancel(reason) { // called if it signals that the stream is to be cancelled } }, queueingStrategy); // { highWaterMark: 1 } |
而构造一个 Response 对象就简单了,Response 对象的第一个参数即是返回值,可以是字符串、Blob、TypedArray,甚至是一个 Stream;而它的第二个参数则和 fetch() 方法很像,也是一些初始化参数。
|
1 2 |
const response = new Response(source, init); |
了解以上的内容后,我们只需要构造一个 ReadableStream,然后把「从 reader 中循环读取数据」的逻辑放在这个流的 start() 方法内,它会在流实例化后立即调用。当 reader 读取数据时可以输出下载进度,同时调用 controller.enqueue() 把得到的数据推进我们构造出来的流,最后在读取完毕时调用 controller.close() 关闭这个流,问题就能轻松解决。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
const logProgress = (res) => { const total = res.headers.get('content-length'); let loaded = 0; const reader = res.body.getReader(); const stream = new ReadableStream({ start(controller) { const push = () => { reader.read().then(({ value, done }) => { if (done) { controller.close(); return; } loaded += value.length; if (total === null) { console.log(`Downloaded ${loaded}`); } else { console.log(`Downloaded ${loaded} of ${total} (${(loaded / total * 100).toFixed(2)}%)`); } controller.enqueue(value); push(); }); }; push(); } }); return new Response(stream, { headers: res.headers }); }; fetch('/foo').then(logProgress).then(res => res.json()).then((data) => { ... }); |
分流一个 ReadableStream
感觉是不是绕了一个远路?就为了这点功能我们居然构造了一个 ReadableStream 实例?有没有更简单的方法?其实是有的,如果你稍有留意的话,应该会注意到 ReadableStream 实例上有一个名字看起来有点奇怪的 tee() 方法。这个方法可以将一个流分流成两个一模一样的流,两个流可以读取完全相同的数据。
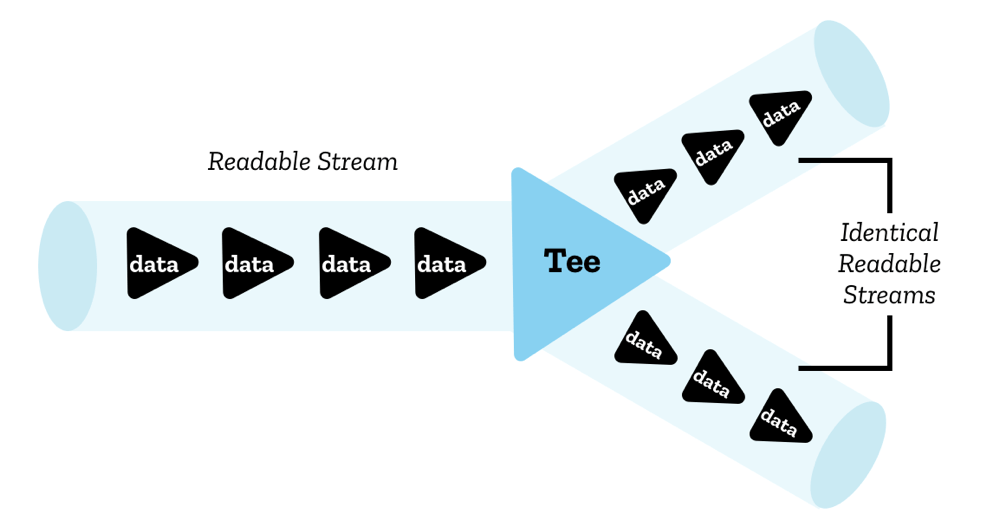
The image of Teeing a ReadableStream by Mozilla Contributors is licensed under CC-BY-SA 2.5.
所以我们可以利用这个特性将一个流分成两个流,将其中一个流用于输出下载进度,而另一个流直接返回:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
const logProgress = (res) => { const total = res.headers.get('content-length'); let loaded = 0; const [progressStream, returnStream] = res.body.tee(); const reader = progressStream.getReader(); const log = () => { reader.read().then(({ value, done }) => { if (done) return; // 省略输出进度 log(); }); }; log(); return new Response(returnStream, { headers: res.headers }); }; fetch('/foo').then(logProgress).then(res => res.json()).then((data) => { ... }); |
可是这样我们还是构造了一个新的 Response 实例,有没有更简单的方法?对不起,其实……还是有的,如果你再稍有留意的话,应该会注意到 Response 实例上有一个一看就知道是什么意思的 clone() 方法。这个方法可以得到一个克隆的 Response 实例(其实这个方法在 Service Worker 里用作请求缓存的情况比较多),所以我们可以将其中一个实例用来获取流并得到下载进度,另一个实例直接返回:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
const logProgress = (res) => { const total = res.headers.get('content-length'); let loaded = 0; const clonedRes = res.clone(); const reader = clonedRes.body.getReader(); const log = () => { reader.read().then(({ value, done }) => { if (done) return; // 省略输出进度 log(); }); }; log(); return res; }; fetch('/foo').then(logProgress).then(res => res.json()).then((data) => { ... }); |
课后习题 Q1:如果我们调用了流的
tee()方法得到了两个流,但我们只读取了其中一个流,另一个流在之后读取,会发生什么吗?
很好,下载进度的问题完美解决了,那么让我们回到最早的问题。Fetch API 最早是没有 signal 这个参数的,所以早期的 fetch 请求很难中断——对,是「很难」,而不是「不可能」。如果浏览器实现了 ReadableStream 并在 Response 上提供了 body 的话,是可以通过流的中断实现这个功能的。
中断一个 ReadableStream
总结一下我们现在已经知道的内容,fetch 请求返回一个 Response 对象,从中可以得到一个 ReadableStream,然后我们还知道了如何自己构造 ReadableStream 和 Response 对象。再回过头看看 ReadableStream 实例上还没提到的方法,想必你一定注意到了那个 cancel() 方法。
通过 ReadableStream 上的 cancel() 方法,我们可以关闭这个流。此外你可能也注意到 reader 上也有一个 cancel() 方法,这个方法的作用是关闭与这个 reader 相关联的流,所以从结果上来看,两者是一样的。而对于 Fetch API 来说,关闭返回的 Response 对象的流的结果就相当于中断了这个请求。
所以,我们可以像之前那样构造一个 ReadableStream 用于传递从 res.body.getReader() 中得到的数据,并对外暴露一个 aborter() 方法。调用这个 aborter() 方法时会调用 reader.cancel() 关闭 fetch 请求返回的流,然后调用 controller.error() 抛出错误,中断构造出来的传递给后续操作的流:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
let aborter = null; const abortHandler = (res) => { const reader = res.body.getReader(); const stream = new ReadableStream({ start(controller) { let aborted = false; const push = () => { reader.read().then(({ value, done }) => { if (done) { if (!aborted) controller.close(); return; } controller.enqueue(value); push(); }); }; aborter = () => { reader.cancel(); controller.error(new Error('Fetch aborted')); aborted = true; }; push(); } }); return new Response(stream, { headers: res.headers }); }; fetch('/foo').then(abortHandler).then(res => res.json()).then((data) => { ... }); aborter(); |
课后习题 Q2:从上面的结果来看,当我们调用
aborter()方法时,请求被成功中止了。不过如果不调用controller.error()抛出错误强制中断流,而是继续之前的流程调用controller.close()关闭流,会发生什么事吗?
流的锁机制
或许你还是很奇怪,既然流本身就有一个 cancel() 方法,为什么我们不直接暴露这个方法,反而要绕路构造一个新的 ReadableStream 呢?
|
1 2 3 4 5 6 7 8 |
let aborter = null; const abortHandler = (res) => { aborter = () => res.body.cancel(); return res; }; fetch('/foo').then(abortHandler).then(res => res.json()).then((data) => { ... }); aborter(); |
可惜这样执行会得到下面的错误:
|
1 2 |
TypeError: Failed to execute 'cancel' on 'ReadableStream': Cannot cancel a locked stream |
什么?流被锁了?你不信邪,既然流的 reader 被关闭时会关闭相关联的流,那么只要再获取一个 reader 并 cancel() 不就好了?
|
1 2 3 4 5 6 7 8 |
let aborter = null; const abortHandler = (res) => { aborter = () => res.body.getReader().cancel(); return res; }; fetch('/foo').then(abortHandler).then(res => res.json()).then((data) => { ... }); aborter(); |
可惜这样执行还是会得到下面的错误:
|
1 2 |
TypeError: Failed to execute 'getReader' on 'ReadableStream': ReadableStreamReader constructor can only accept readable streams that are not yet locked to a reader |
或许你还会想,像之前那样克隆一个流,然后关闭克隆的流不就好了?可惜被使用的流是不能被克隆的,即便在使用前先克隆一个流,你也会发现即便成功调用了 close() 方法,请求还是没有中断,因为另一个流并没有被中断,还是可以接收数据的。
于是我们第一次接触到了流的锁机制。一个流只能同时有一个活跃的 reader,当一个流被一个 reader 使用时,这个流就被该 reader 锁定了,此时流的 locked 属性为 true。如果这个流需要被另一个 reader 读取,那么当前活跃的 reader 可以调用 reader.releaseLock() 方法释放锁。
此外 reader 的 closed 属性是一个 Promise,当 reader 被关闭或者释放锁时,这个 Promise 会被 resolve,可以在这里编写关闭 reader 的处理逻辑:
|
1 2 3 4 5 |
reader.closed.then(() => { console.log('reader closed'); }); reader.releaseLock(); |
可是上面的代码似乎没用上 reader 啊?再仔细思考下 res => res.json() 这段代码,是不是有什么启发?
让我们翻一下 Fetch API 的规范文档,在 5.2. Body mixin 中有如下一段话:
Objects implementing the
Bodymixin also have an associated consume body algorithm, given a type, runs these steps:
- If this object is disturbed or locked, return a new promise rejected with a
TypeError.Let stream be body’s stream if body is non-null, or an empty
ReadableStreamobject otherwise.Let reader be the result of getting a reader from stream. If that threw an exception, return a new promise rejected with that exception.
Let promise be the result of reading all bytes from stream with reader.
Return the result of transforming promise by a fulfillment handler that returns the result of the package data algorithm with its first argument, type and this object’s MIME type.
简单来说,当我们调用 Body 上的方法时,浏览器隐式地创建了一个 reader 读取了返回数据的流,并创建了一个 Promise 实例,待所有数据被读取完后再 resolve 并返回格式化后的数据。所以,当我们调用了 Body 上的方法时,其实就创建了一个我们无法接触到的 reader,此时这个流就被锁住了,自然也无法从外部取消。
示例:断点续传
现在我们可以随时中断一个请求,以及获取到请求过程中的数据,甚至还能修改这些数据。或许我们可以用来做些有趣的事情,比如各个下载器中非常流行的断点续传功能。
首先我们先来了解下断点续传的原理,简述如下:
- 发起请求
- 从响应头中拿到
Content-Length属性 - 在响应过程中拿到正在下载的数据
- 终止下载
- 重新下载,但是此时根据已经拿到的数据设置
Range请求头 - 重复步骤 3-5,直至下载完成
- 下载完成,将已拿到的数据拼接成完整的
在过去只能使用 XMLHttpRequest 或者还没有 Stream API 的时候,我们只能在请求完成时拿到数据。如果期间请求中断了,那也不会得到已经下载的数据,也就是这部分请求的流量被浪费了。所以断点续传最大的问题是获取已拿到的数据,也就是上面的第 3 步,根据已拿到的数据就能算出还有哪些数据需要请求。
其实在 Streams API 诞生之前,大家已经有着各种各样奇怪的方式实现断点续传了。来自新西兰的 Mega 网盘可以说是最佳 webapp 之一了,且不提它的加密功能,在浏览器中下载文件时它不会立即让浏览器下载文件,而是将数据放在浏览器内,待所有数据下载完成后再让浏览器下载文件,而这样的特性让 Mega 网盘可以实现断点续传的功能。不过刚刚不是提到 XHR 是不支持拿到请求中断时的数据吗?那么这个功能是怎么实现的?
仔细观察网络请求就会发现,Mega 在下载时不是下载整个文件,而是在请求的 URL 中包含了一个 Range 参数,表明需要拉取文件的哪一个片段。所以 Mega 是通过建立多个小的请求获取文件的各个小区块,待下载完成后再拼接为一个大文件。即便用户中途暂停,已下载的块也不会丢失,继续下载时会重新请求未完成的区块。不过这样会频繁建立多个 HTTP 请求(当然一般是 keep-alive 的,所以应该不用考虑重建 TCP 连接),而且其实在暂停时,正在下载的区块还是会被丢弃。不过相比较于丢弃整个文件来说,现在的实现已经是很大的优化了。
此节文本可能包含一些业务上的功能逻辑,由于本人并未接触相关代码,仅能从浏览器的请求结果上分析,所以可能存在问题
除了主动获取小区块变相实现断点续传外,其实 Firefox 浏览器上的私有特性允许开发者获取正在下载的文件片段,而云音乐就使用了该特性优化了 Firefox 浏览器上的音频文件请求。
Firefox 浏览器的 XMLHttpRequest 为 responseType 属性提供了私有的可用参数 moz-chunked-arraybuffer。请求还未完成时,可以在 progress 事件中请求 XHR 实例的 response 属性,它将会返回目前已经接收到的所有数据,而在 progress 事件外获取该属性将始终是 null。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
let chunks; const xhr = new XMLHttpRequest(); xhr.open('GET', '/foo'); xhr.responseType = 'moz-chunked-arraybuffer'; xhr.addEventListener('progress', (event) => { chunks = xhr.response; }); xhr.addEventListener('abort', () => { const blob = new Blob(chunks); }); xhr.send(); |
看起来是个很不错的特性,只可惜在 Bugzilla 上某个 和云音乐相关的 issue 里,有人用 Mozilla 的 debug 工具 mozregression 发现这个特性已经在 Firefox 68 中移除了。
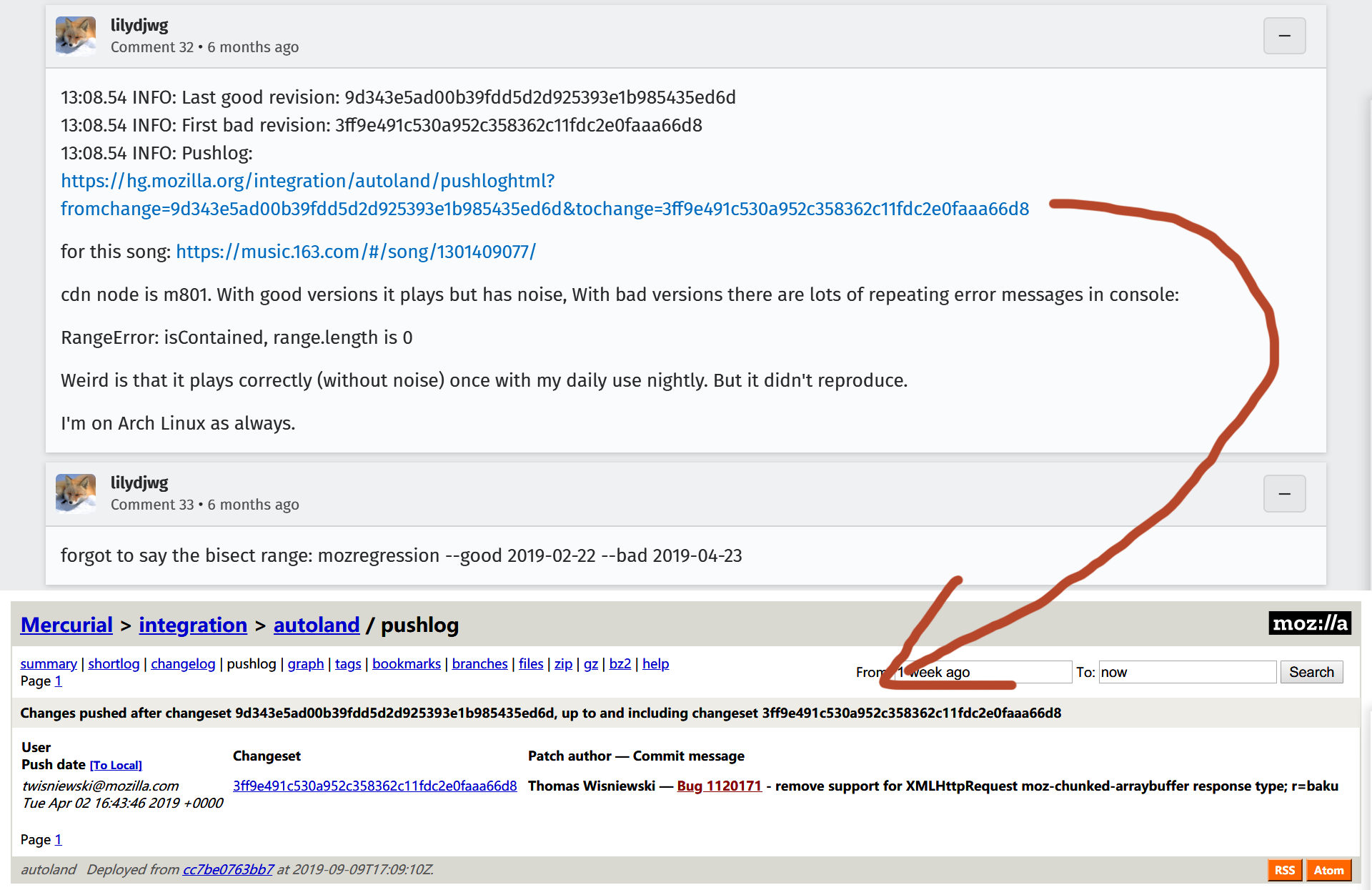
原因也可以理解,Firefox 现在已经在 fetch 上实现 Stream API 了,有标准定义当然还是跟着标准走(虽然至今还是 LS 阶段),所以也就不再需要这些私有属性了。
从之前的示例我们已经知道,我们可以从 fetch 请求返回的 ReadableStream 里得到正在下载的数据区块,那么只要在请求的过程中把它们放在一个类似缓冲区的地方就可以实现之前的第 3 步了。请求中断后再次请求时,只需要根据已下载区块的字节数就可以算出接下来要请求哪些区块了。待全部下载完成后,再将已下载的数据拼接返回,就能得到完整的数据了。简单来看,逻辑大概是下面这样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
const chunks = []; let length = 0; const chunkCache = (res) => { const total = res.headers.get('content-length'); const reader = res.body.getReader(); const stream = new ReadableStream({ start(controller) { const push = () => { reader.read().then(({ value, done }) => { if (done) { let chunk; while (chunk = chunks.shift()) { controller.enqueue(chunk); } controller.close(); return; } chunks.push(value); length += value.length; push(); }); }; push(); } }); return new Response(stream, { headers: res.headers }); }; const controller = new AbortController(); fetch('/foo', { headers: { 'Range': `bytes=${length}-` }, signal: controller.signal }).then(chunkCache).then(...); // 请求中断后再次执行上述 fetch() 方法 |
下面的例子对上述代码简单封装得到了 ResumableFetch,并使用它实现了图片下载的断点续传。示例完整代码可在 CodePen 上查看。
See the Pen Resumable Fetch Example by ccloli (@ccloli) on CodePen.dark
注意:该示例中的代码仅进行了简单封装,没有做诸如
If-Range、Range和Content-Length等 header 的校验,也没有做特殊的错误处理,也没有包含之前提到的中断请求兼容代码,使用上可能也不够友好,仅供示例使用,请谨慎用于生产环境,未来可能会完善功能后单独发布 npm 包。
封装的 ResumableFetch 类会在请求过程中创建一个 ReadableStream 实例并直接返回,同时已下载的片段将会放进一个数组 chunks 并记录已下载的文件大小 length。当请求中断并重新下载时会根据已下载的文件大小设置 Range 请求头,此时拿到的就是还未下载的片段。下载完成后再将片段从 chunks 中取出,此时不需要对片段进行处理,只需要逐一传递给 ReadableStream 即可得到完整的文件。
管道
到这里 ReadableStream 上的方法已经描述的差不多了,最后只剩下 pipeTo() 方法和 pipeThrough() 方法没有提到了。从字面意思上来看,这就是我们之前提到的管道,可以将流直接指向另一个流,最后拿到处理后的数据。Jake Archibald 在他的那篇《2016 — 属于 web streams 的一年》中提出了下面的例子,或许在(当时的)未来可以通过这样的形式以流的形式得到解析后的文本:
|
1 2 3 4 5 6 |
var reader = response.body .pipeThrough(new TextDecoder()).getReader(); reader.read().then(result => { // result.value will be a string }); |
现在那个未来已经到了,为了不破坏兼容性,TextEncoder 和 TextDecoder 分别扩展出了新的 TextEncoderStream 和 TextDecoderStream,允许我们以流的方式编码或者解码文本。例如下面的例子会在请求中检索 It works! 这段文字,当找到这段文字时返回 true 同时断开请求。此时我们不需要再接收后续的数据,可以减少请求的流量:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
fetch('/index.html').then((res) => { const decoder = new TextDecoderStream('gbk', { ignoreBOM: true }); const textStream = res.body.pipeThrough(decoder); const reader = textStream.getReader(); const findMatched = () => reader.read().then(({ value, done }) => { if (done) { return false; } if (value.indexOf('It works!') >= 0) { reader.cancel(); return true; } return findMatched(); }); return findMatched(); }).then((isMatched) => { ... }); |
或者在未来,我们甚至在流里实现实时转码视频并播放,或者将浏览器还不支持的图片以流的形式实时渲染出来:
|
1 2 3 4 5 6 7 8 9 10 |
const encoder = new VideoEncoder({ input: 'gif', output: 'h264' }); const media = new MediaStream(); const video = document.createElement('video'); fetch('/sample.gif').then((res) => { response.body.pipeThrough(encoder).pipeTo(media); video.srcObject = media; }); |
从中应该可以看出来这两种方法的区别:pipeTo() 方法应该会接受一个可以写入的流,也就是 WritableStream;而 pipeThrough() 方法应该会接受一个既可写入又可读取的流,也就是 TransformStream。
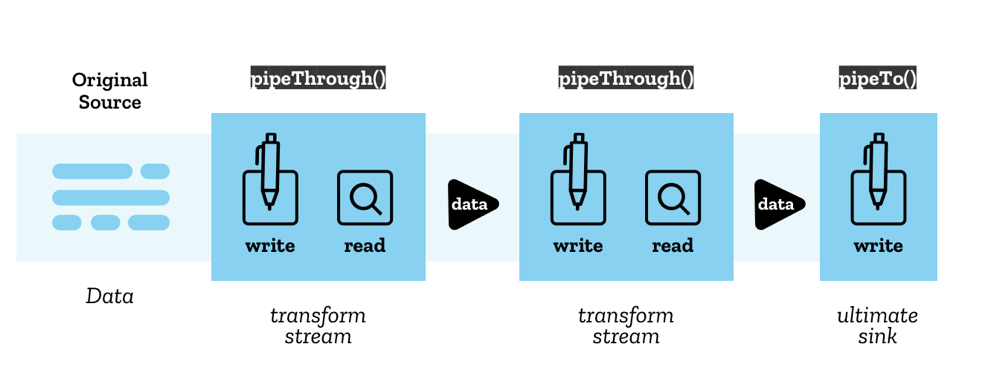
The image of Stream Pipe Chains Concept by Mozilla Contributors is licensed under CC-BY-SA 2.5.
接下来我们将介绍这两种流,不过在继续之前,我们先来看看 ReadableStream 在浏览器上的支持程度:
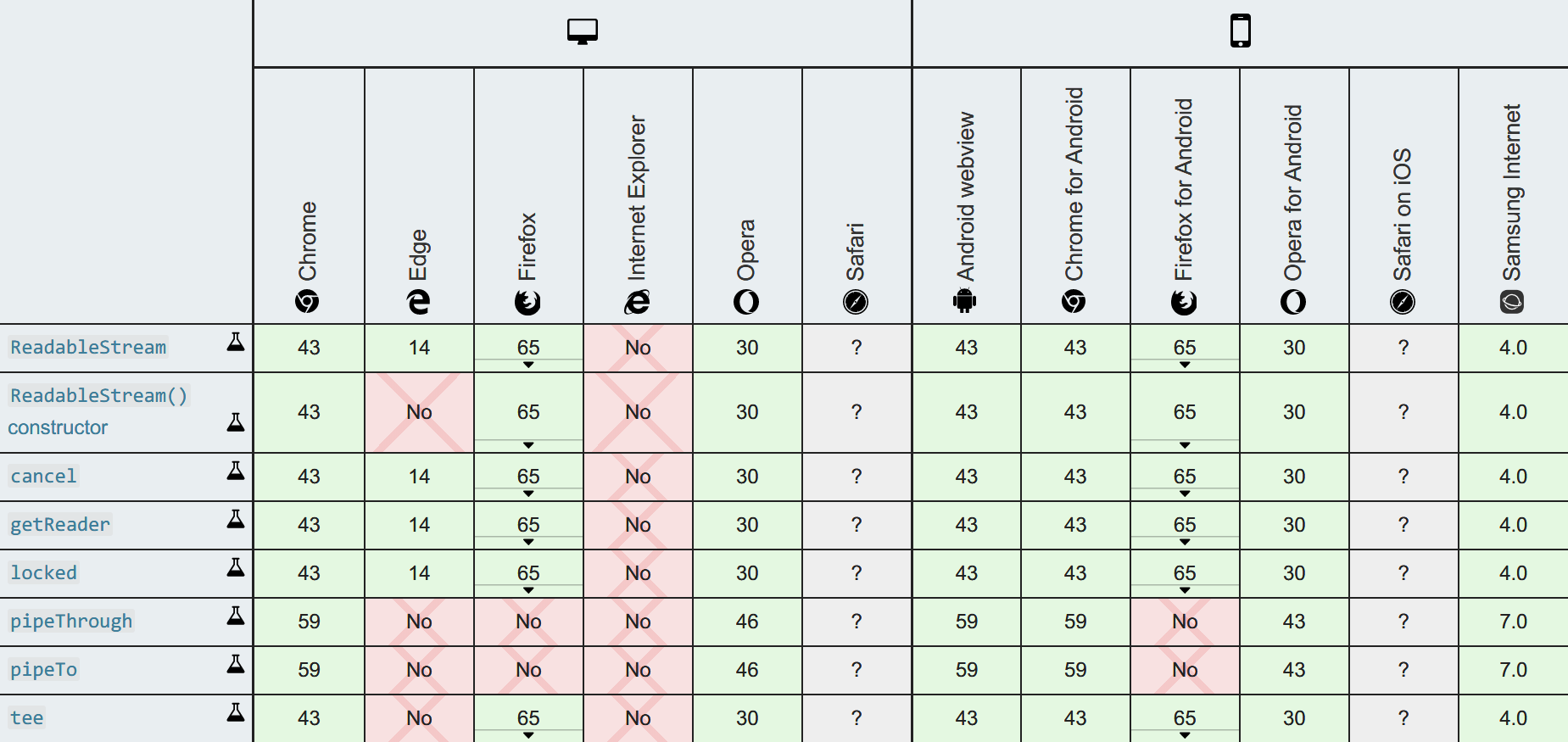
Image of Stream API Browser Compatibilty Table by Mozilla Contributors is licensed under CC-BY-SA 2.5.
从表中我们注意到,这两个方法支持的比较晚。而原因估计你也能猜得到,当数据从一个可读取的流中流出时,管道的另一端应该是一个可写入的流,问题就在于可写入的流实现的比较晚。
WritableStream
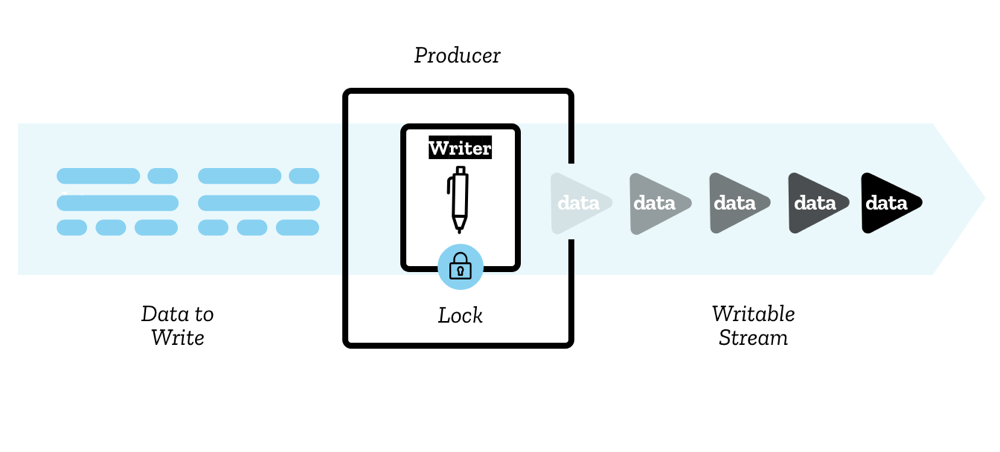
The image of WritableStream Concept by Mozilla Contributors is licensed under CC-BY-SA 2.5.
我们已经从 ReadableStream 中了解到很多关于流的知识了,所以下面我们简单过一下 WritableStream。WritableStream 就是可写入的流,如果说 ReadableStream 是一个流的起点,那么 WritableStream 可以理解为流的终点。下面是一个 WritableStream 实例上的参数和可以使用的方法:
WritableStream
– locked
– abort()
– getWriter()
可用的方法和参数很少,估计大家从名字就能知道它们是做什么的。其中直接调用 getWriter() 方法会得到一个 WritableStreamDefaultWriter 实例,通过这个实例我们就能向 WritableStream 写入数据。同样的,当我们激活了一个 writer 后,这个流就会被锁定(locked = true)。这个 writer 上有如下属性和方法:
WritableStreamDefaultWriter
– closed
– desiredSize
– ready
– abort()
– close()
– write()
– releaseLock()
看起来和 ReadableStreamDefaultReader 没太大区别,多出的 abort() 方法相当于抛出了一个错误,使这个流不能再被写入。另外这里多出了一个 ready 属性,这个属性是一个 Promise,当它被 resolve 时,表明目前流的缓冲区队列不再过载,可以安全地写入。所以如果需要循环向一个流写入数据的话,最好放在 ready 处理。
同样的,我们可以自己构造一个 WritableStream,构造时可以定义以下方法和参数:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
const stream = new WritableStream({ start(controller) { // called immediately when the object is constructed controller.error(reason) // cause an error to stream }, write(chunk, controller) { // called when a new chunk of data is ready to be written }, close(controller) { // called if it signals that the stream has finished writing }, abort(reason) { // called if it signals that it wishes to abruptly close the // stream and put it in an errored state } }, queueingStrategy); // { highWaterMark: 1 } |
下面的例子中,我们通过循环调用 writer.write() 方法向一个 WritableStream 写入数据:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const stream = new WritableStream({ write(chunk) { return new Promise((resolve) => { console.log('got chunk:', chunk); // ...... resolve(); }); }, close() { console.log('stream closed'); }, abort() { console.log('stream aborted'); } }); const writer = stream.getWriter(); // 将数据逐一写入 stream data.forEach((chunk) => { writer.ready.then(() => { writer.write(chunk); }); }); // 在关闭 writer 前先保证所有的数据已经被写入 writer.ready.then(() => { writer.close(); }); |
下面是 WritableStream 的浏览器支持情况,可见 WritableStream 在各个浏览器上的的实现时间和 pipeTo() 与 pipeThrough() 方法的实现时间是吻合的,毕竟要有了可写入的流,管道才有存在的意义。
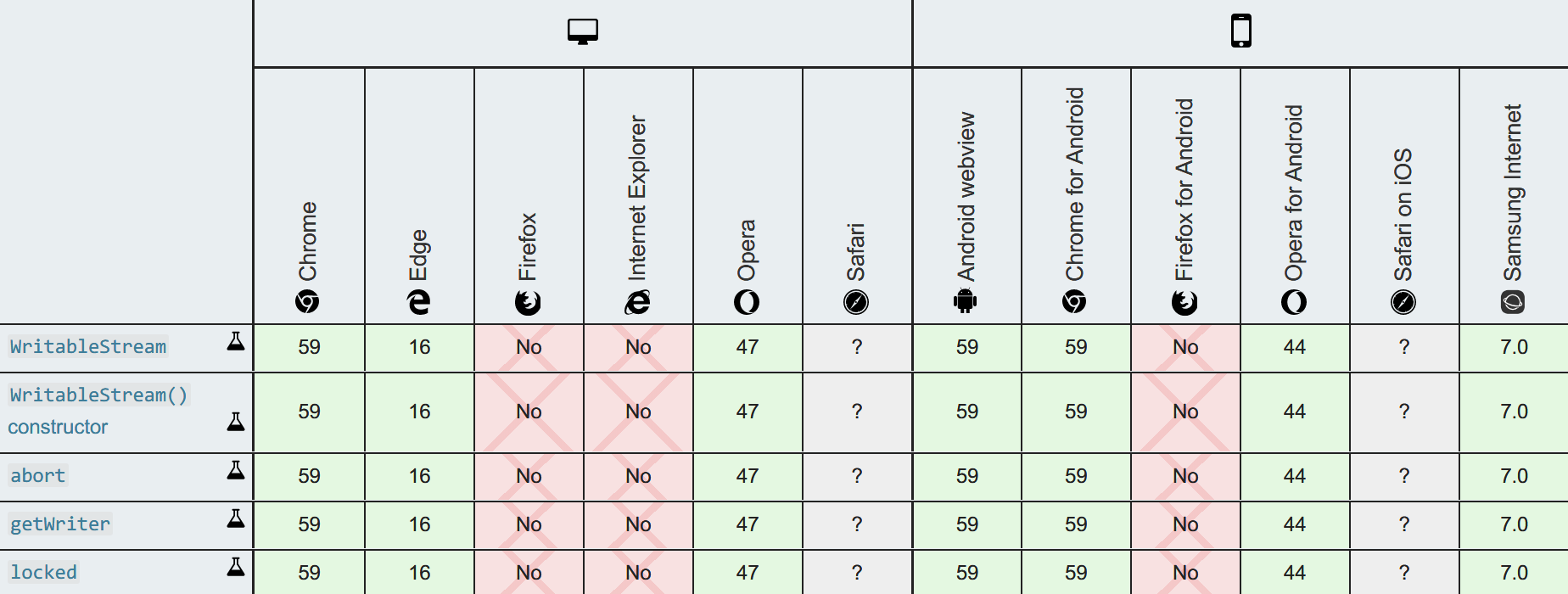
Image of Stream API Browser Compatibilty Table by Mozilla Contributors is licensed under CC-BY-SA 2.5.
TransformStream
从之前的介绍中我们知道,TransformStream 是一个既可写入又可读取的流,正如它的名字一样,它作为一个中间流起着转换的作用。所以一个 TransformStream 实例只有如下参数:
TransformStream
– readable: ReadableStream
– writable: WritableStream
TransformStream 上没有其他的方法,它只暴露了自身的 ReadableStream 与 WritableStream。我们只需要在数据源流上链式使用 pipeThrough() 方法就能实现流的数据传递,或者使用暴露出来的 readable 和 writable 直接操作数据即可使用它。
TransformStream 的处理逻辑主要在流内部实现,下面是构造一个 TransformStream 时可以定义的方法和参数:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
const stream = new TransformStream({ start(controller) { // called immediately when the object is constructed controller.desiredSize // the desired size required to fill the queue controller.enqueue(chunk) // enqueue a given chunk in the readable side controller.error(reason) // error both the readable side and the writable side controller.terminate() // close the readable side and error the writable side }, transform(chunk, controller) { // called when a new chunk will be transformed to the writable side }, flush(controller) { // called after all chunks written to the writable side // have been transformed by successfully passing through // transform(), and the writable side is about to be closed } }, queueingStrategy); // { highWaterMark: 1 } |
有了 ReadableStream 与 WritableStream 作为前置知识,TransformStream 就不需要做太多介绍了。下面的示例代码摘自 MDN,是一段实现 TextEncoderStream 和 TextDecoderStream 的 polyfill,本质上只是对 TextEncoder 和 TextDecoder 进行了一层封装:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
const tes = { start() { this.encoder = new TextEncoder() }, transform(chunk, controller) { controller.enqueue(this.encoder.encode(chunk)) } } let _jstes_wm = new WeakMap(); /* info holder */ class JSTextEncoderStream extends TransformStream { constructor() { let t = { ...tes } super(t) _jstes_wm.set(this, t) } get encoding() { return _jstes_wm.get(this).encoder.encoding } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
const tes = { start() { this.decoder = new TextDecoder(this.encoding, this.options) }, transform(chunk, controller) { controller.enqueue(this.decoder.decode(chunk)) } } let _jstds_wm = new WeakMap(); /* info holder */ class JSTextDecoderStream extends TransformStream { constructor(encoding = 'utf-8', { ...options } = {}) { let t = { ...tds, encoding, options } super(t) _jstes_wm.set(this, t) } get encoding() { return _jstds_wm.get(this).decoder.encoding } get fatal() { return _jstds_wm.get(this).decoder.fatal } get ignoreBOM() { return _jstds_wm.get(this).decoder.ignoreBOM } } |
The source code of Polyfilling TextEncoderStream and TextDecoderStream by Mozilla Contributors is licensed under CC-BY-SA 2.5 or CC0.
到这里我们已经把 Streams API 中所提供的流浏览了一遍,最后是 caniuse 上的浏览器支持数据,可见目前 Streams API 的支持度不算太差,至少主流浏览器都支持了 ReadableStream,读取流已经不是什么问题了,可写入的流使用场景也比较少。不过其实问题不是特别大,我们已经简单知道了流的原理,做一些简单的 polyfill 或者额外写些兼容代码应该也是可以的,毕竟已经有不少第三方实现了。
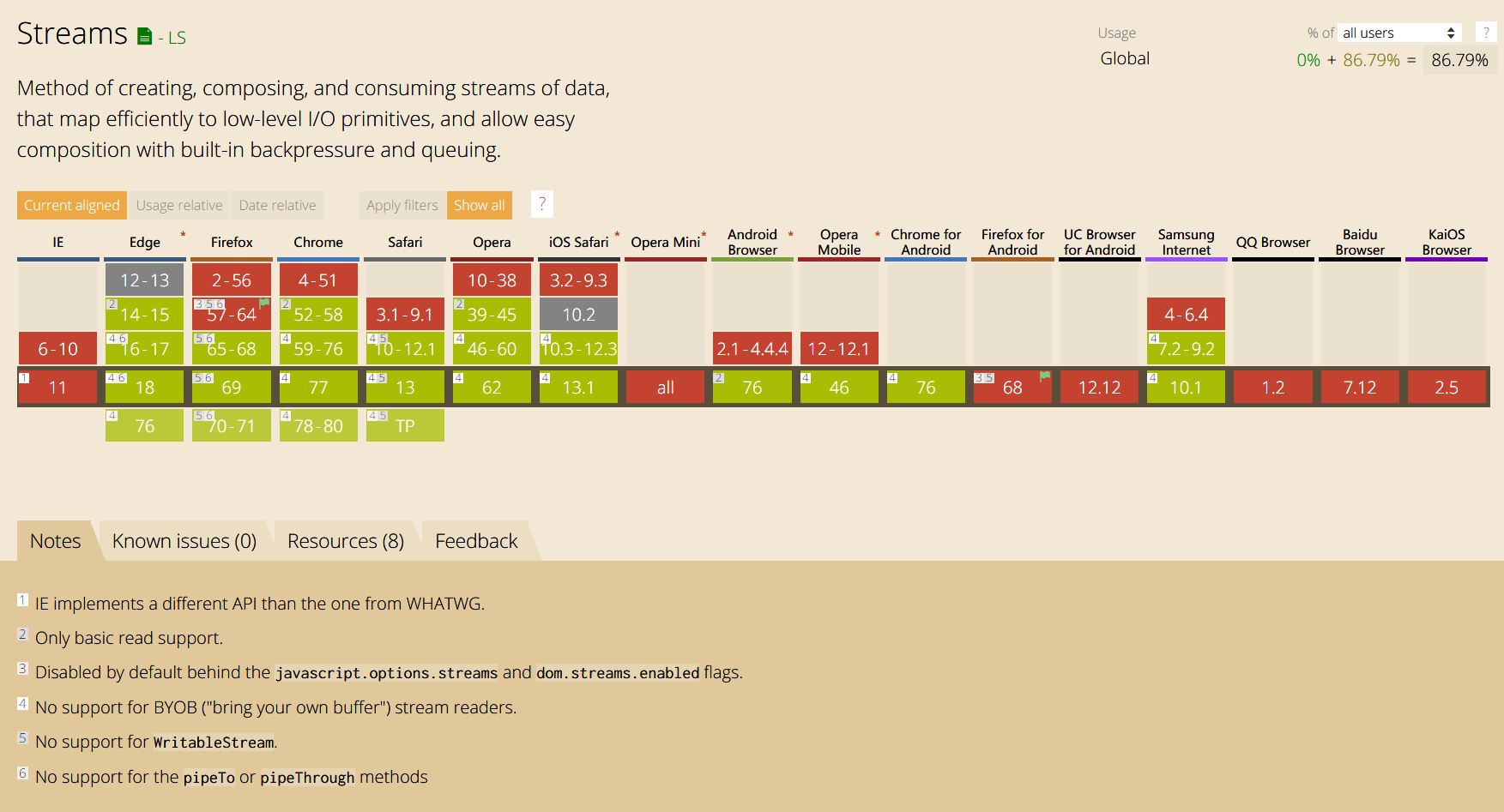
Image of Streams Support Table by caniuse.com is licensed under CC-BY 4.0.
在 Service Worker 中使用 Streams API
首先让我们来模拟体验一下龟速到只有大约 30B/s 的网页看起来是什么样子的:
其实这是借助 Service Worker 的 fetch 事件配合 Streams API 实现的。熟悉 Service Worker 的同学应该知道 Service Worker 里有一个 fetch 事件,可以在事件内捕获到页面所有的请求,fetch 事件的事件对象 FetchEvent 中包含如下参数和方法:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
addEventListener('fetch', (fetchEvent) => { fetchEvent.clientId // The id of the same-origin client fetchEvent.preloadResponse // A Promise for a preload Response fetchEvent.request // The Request the browser intends to make fetchEvent.replacesClientId // The id of the client that's being replaced // during a page navigation fetchEvent.resultingClientId // The id of the client that replaces the previous // client during a page navigation fetchEvent.respondWith() // Prevent the browser's default fetch handling, // and provide (a promise for) a response yourself fetchEvent.waitUntil() // Extends the lifetime of the event, // like do something beyond the returning }); |
使用 Service Worker 最常见的例子是借助 fetch 事件实现中间缓存甚至离线缓存。我们可以调用 caches.open() 打开或者创建一个缓存对象 cache,如果 cache.match(event.request) 有缓存的结果时,可以调用 event.respondWith() 方法直接返回缓存好的数据;如果没有缓存的数据,我们再在 Service Worker 里调用 fetch(event.request) 发出真正的网络请求,请求结束后我们再在 event.waitUntil() 里调用 cache.put(event.request, response.clone()) 缓存响应的副本。由此可见,Service Worker 在这之间充当了一个中间人的角色,可以捕获到页面发起的所有请求,然后根据情况返回缓存的请求,所以可以猜到我们甚至可以改变预期的请求,返回另一个请求的返回值。
Streams API 在 Service Worker 中同样可用,所以我们可以在 Service Worker 里监听 fetch 事件,然后用上我们之前学习到的知识,改变 fetch 请求的返回结果为一个速度很缓慢的流。这里我们让这个流每隔约 30 ms 才吐出 1 个字节,最后就能实现上面视频中的效果:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
globalThis.addEventListener('fetch', (event) => { event.respondWith((async () => { const response = await fetch(event.request); const { body } = response; const reader = body.getReader(); const stream = new ReadableStream({ start(controller) { const sleep = time => new Promise(resolve => setTimeout(resolve, time)); const pushSlowly = () => { reader.read().then(async ({ value, done }) => { if (done) { controller.close(); return; } const length = value.length; for (let i = 0; i < length; i++) { await sleep(30); controller.enqueue(value.slice(i, i + 1)); } pushSlowly(); }); }; pushSlowly(); } }); return new Response(stream, { headers: response.headers }); })()); }); |
看着不是很实用?那么再举一个比较实用的例子吧。如果我们需要让用户在浏览器中下载一个文件,一般都是会指向一个服务器上的链接,然后浏览器发起请求从服务器上下载文件。那么如果我们需要让用户下载一个在客户端生成的文件,比如从 canvas 上生成的图像,应该怎么办呢?其实让客户端主动下载文件已经有现成的库 FileSaver.js 实现了,它的原理可以用下面的代码简述:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
const a = document.createElement('a'); const blob = new Blob(chunk, options); const url = URL.createObjectURL(blob); a.href = url; a.download = 'filename'; const event = new MouseEvent('click'); a.dispatchEvent(event); setTimeout(() => { URL.revokeObjectURL(url); if (blob.close) blob.close(); }, 1e3); |
这里利用了 HTML 标签上的 download 属性,当链接存在该属性时,浏览器会将链接的目标视为一个需要下载的文件,链接不会在浏览器中打开,转而会将链接的内容下载到设备的硬盘上。此外在浏览器中还有 Blob 对象,它相当于一个类似文件的二进制数据对象(File 就是继承于它)。我们可以将需要下载的数据(无论是什么类型,字符串、TypedArray 甚至是其他 Blob 对象)传进 Blob 的构造函数里,这样我们就得到了一个 Blob 对象。最后我们再通过 URL.createObjectURL() 方法可以得到一个 blob: 开头的 Blob URL,将它放到有 download 属性的 链接上,并触发鼠标点击事件,浏览器就能下载对应的数据了。
顺带一提,在最新的 Chrome 76 和 Firefox 69 上,
Blob实例支持了stream()方法,它将返回一个ReadableStream实例。所以现在我们终于可以直接以流的形式读取文件了——看,只要ReadableStream实现了,相关的原生数据流源也会完善,其他的流或许也只是时间问题而已。
不过问题来了,如果需要下载的文件数据量非常大,比如这个数据是通过 XHR/Fetch 或者 WebRTC 传输得到的,直接生成 Blob 可能会遇到内存不足的问题。甚至 在 Chrome 57 之前,整个浏览器内只能使用最大 500 MB 的共享 Blob Storage。如果超出了可用空间,Chrome 浏览器会返回一个没有任何数据的 Blob 对象,Firefox 浏览器会抛出 NS_ERROR_OUT_OF_MEMORY 错误。再加上更早以前的 Blob 实例上是没有主动释放内存的 close() 方法的,你只能调用 URL.revokeObjectURL() 来去除所有的引用,然后祈祷浏览器的黑盒会在什么时候 GC 掉它。
下面是一个比较极端的糟糕例子,它描述了客户端打包下载图片的流程。客户端 JavaScript 发起多个请求得到多个文件,然后通过 JSZip 这个库生成了一个巨大的 ArrayBuffer 数据,这个数据就是一个 zip 文件。接下来就像之前提到的那样,我们构造了一个 Blob 对象并用 FileSaver.js 下载了这个图片。如你所见,所有的数据都是存放在内存中的,而在生产 zip 文件时,我们又占用了近乎一样大小的内存空间。最后正如下图黄色部分指示的那样一样,这样的实现可能会在浏览器内占用 2-3 倍的内存空间,即便使用 Chrome 私有的 File System API 来缓解 Blob Storage 容量的问题,也无法解决内存占用的问题。
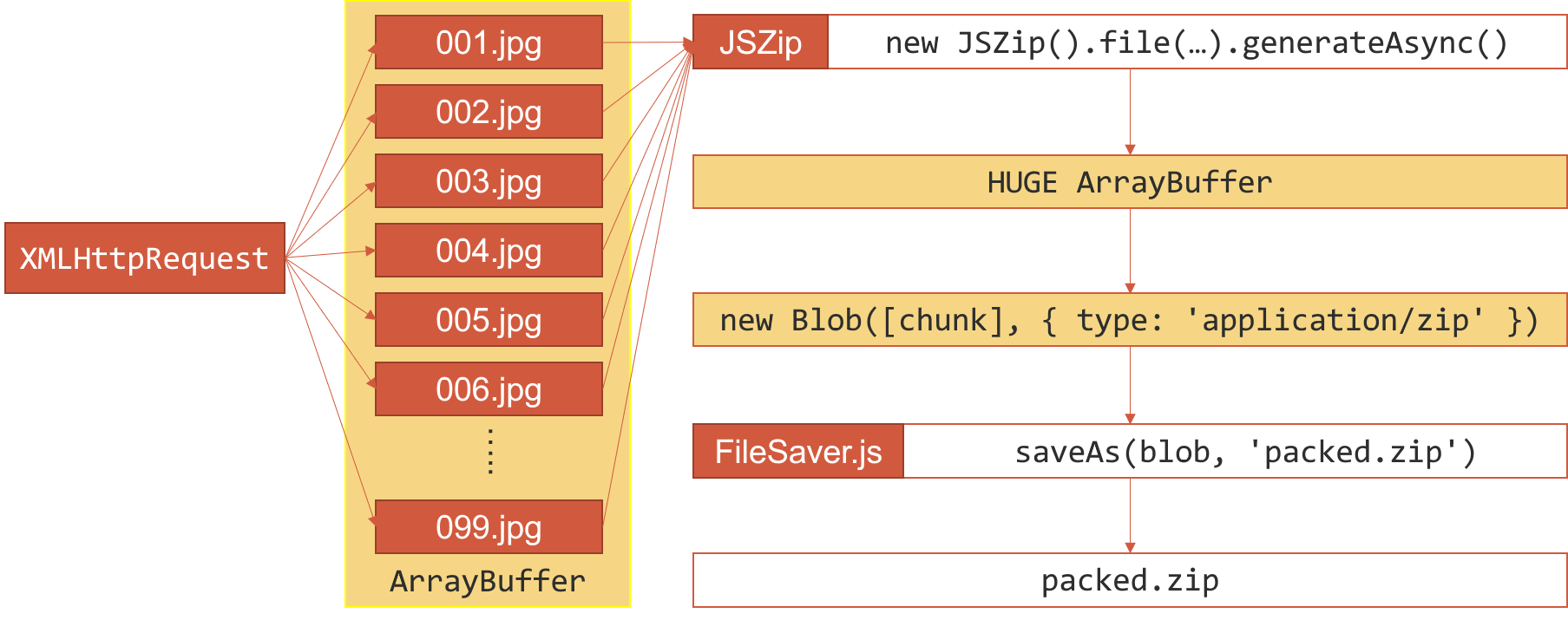
我们之前提到的 Mega 网盘也是一样的情况,它将所有的数据都放在浏览器内,直到下载完成时才会交给用户肯定也会遇到一样的问题。毕竟除了为了断点续传外,按照 Mega 网盘的说法,传输的数据是加密过的,所以需要在浏览器内解密并拼合后才能拿到实际的文件数据。从 Mega 的 源码 里可以看出它做了非常多的优化来绕过浏览器的限制:
|
1 2 3 4 5 6 7 8 9 |
var dl_method; // 0: Filesystem API (Chrome / Firefox Extension polyfill // 1: Adobe Flash SWF Filewriter (fallback for old browsers) // 2: BlobBuilder (IE10/IE11) // 3: Deprecated MEGA Firefox Extension // 4: Arraybuffer/Blob Memory Based // 5: MediaSource (experimental streaming solution) // 6: IndexedDB blob based (Firefox 20+) |
现在有了 Streams API,我们就有了另一种解决方式。StreamSaver.js 就是这样的一个例子,它借助了 Streams API 和 Service Worker 解决了内存占用过大的问题。阅读它的源码,可以看出它的工作流程类似下面这样:
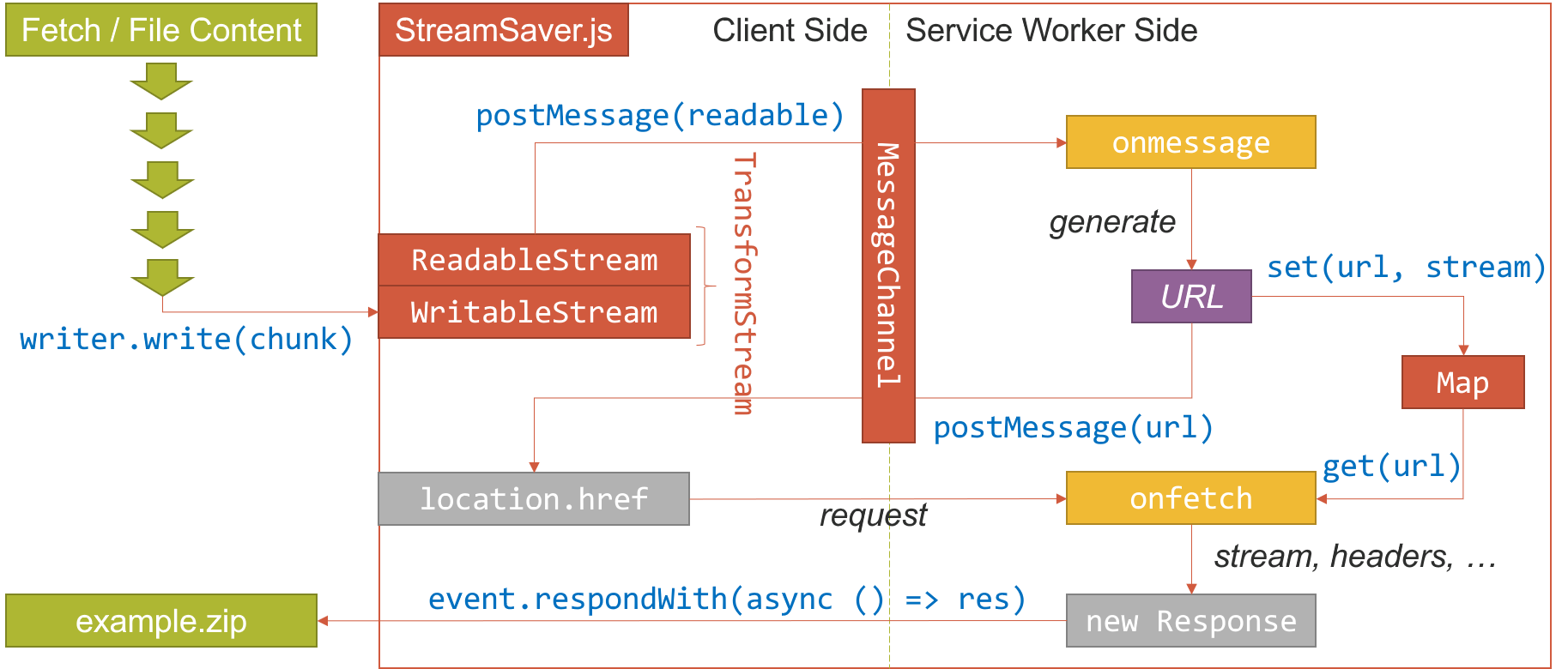
StreamSaver.js 包含两部分代码,一部分是客户端代码,一部分是 Service Worker 的代码(对于不支持 Service Worker 的情况,作者在 GitHub Pages 上提供了一个运行 Service Worker 的页面供跨域使用)。在初始化时客户端代码会创建一个 TransformStream 并将可写入的一端封装为 writer 暴露给外部使用,在脚本调用 writer.write(chunk) 写入文件片段时,客户端会和 Service Worker 之间建立一个 MessageChannel,并将之前的 TransformStream 中可读取的一端通过 port1.postMessage() 传递给 Service Worker。Service Worker 里监听到通道的 onmessage 事件时会生成一个随机的 URL,并将 URL 和可读取的流存入一个 Map 中,然后将这个 URL 通过 port2.postMessage() 传递给客户端代码。客户端接收到 URL 后会控制浏览器跳转到这个链接,此时 Service Worker 的 onfetch 事件接收到这个请求,将 URL 和之前的 Map 存储的 URL 比对,将对应的流取出来,再加上一些让浏览器认为可以下载的响应头(例如 Content-Disposition)封装成 Response 对象,最后通过 event.respondWith() 返回。这样在当客户端将数据写入 writer 时,经过 Service Worker 的流转,数据可以立刻下载到用户的设备上。这样就不需要分配巨大的内存来存放 Blob,数据块经过流的流转后直接被回收了,降低了内存的占用。
事实上,现在的 Firefox Send 对支持的浏览器就使用了类似上述的流程实现,当用户下载文件时会发出请求,Service Worker 接收到下载请求后会建立真实的 fetch 请求连接服务器,将返回的数据实时解密后直接下载到用户的设备上。这样的直观效果是,浏览器直接下载了文件,文件会显示在浏览器的下载列表中,同时页面上还会有下载进度:

所以借助 StreamSaver.js,之前下载图片的流程可以优化如下:JSZip 提供了一个 StreamHelper 的接口来模拟流的实现,所以我们可以调用 generateInternalStream() 方法以小文件块的形式接收数据,每次接收到数据时数据会写入 StreamSaver.js 的 writer,经过 Service Worker 后数据直接被下载。这样就不会再像之前那样在生成 zip 时占用大量的内存空间了,因为 zip 数据在实时生成时被划分成了小块并迅速被处理掉了。
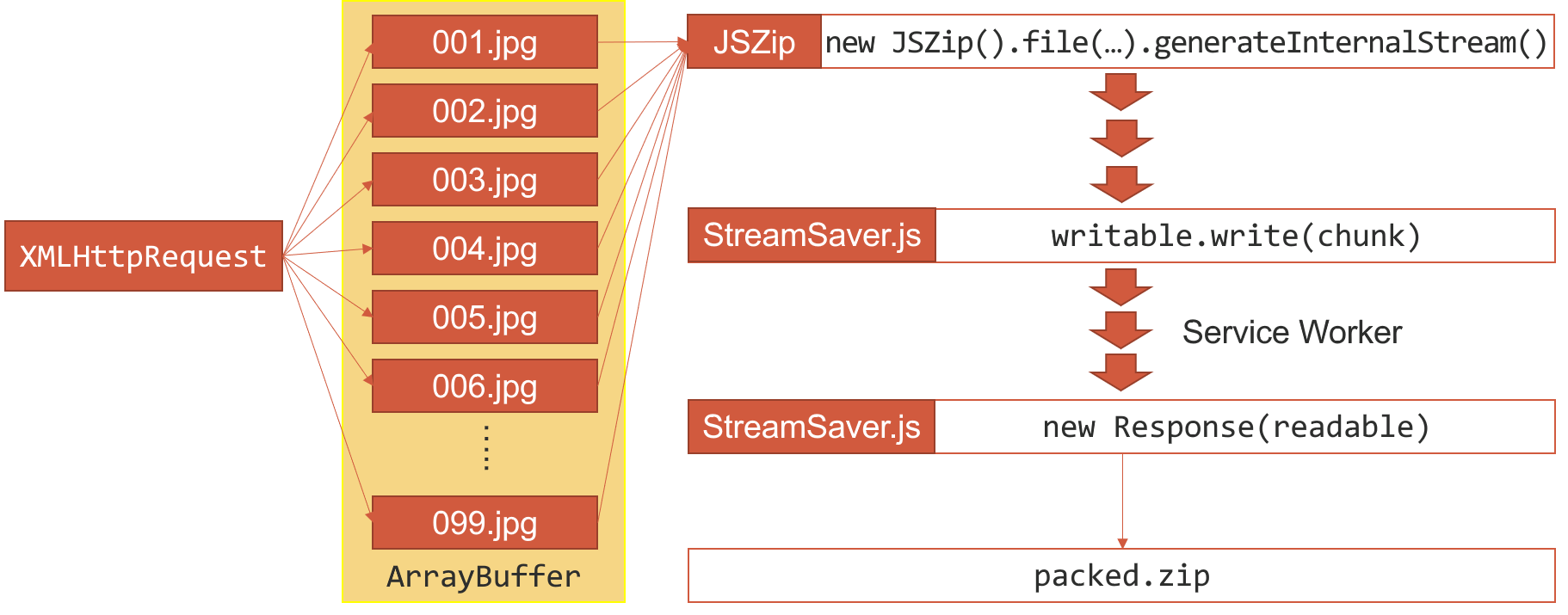
课后习题 Q3:StreamSaver.js 在不支持
TransformStream的浏览器下其实是可以正常工作的,这是怎么实现的呢?
总结
经过了这么长时间的学习,我们从 Fetch API 的角度出发探索 Streams API,大致了解了以下几点:
- Streams API 允许我们以流的形式实时处理数据,每次只需要处理数据的一小部分
- 可以使用
pipeTo()、pipeThrough()方法方便地将多个流连接起来 ReadableStream是可读取的流,WritableStream是可写入的流,TransformStream是既可写入又可读取的流- Fetch API 的返回值是一个
Response对象,它的body属性是一个ReadableStream - 借助 Streams API 我们可以实现中断 fetch 请求或者计算 fetch 请求的下载速度,甚至可以直接对返回的数据进行修改
- 我们学习了如何构造一个流,并将其作为 fetch 请求的返回值
- 在 Service Worker 里也可以使用 Streams API,使用
onfetch事件可以监听所有的请求,并对请求进行篡改 - 顺带了解了如何中断一个 fetch 请求,使用
download属性下载文件,Blob对象,MessageChannel双向通信……
Streams API 提出已经有很长一段时间了,由于浏览器支持的原因再加上使用场景比较狭窄的原因一直没有得到广泛使用,国内的相关资料也比较少。随着浏览器支持逐渐铺开,浏览器原生提供的可读取流和可写入流也会逐渐增加(比如在本文即将写成时才注意到 Blob 对象已经支持 stream() 方法了),能使用上的场景也会越来越多,让我们拭目以待吧。
参考答案
- Q1. 如果我们调用了流的
tee()方法得到了两个流,但我们只读取了其中一个流,另一个流在之后读取,会发生什么吗?使用
tee()方法分流出来的两个流之间是相互独立的,所以被读取的流会实时读取到传递的数据,过一段时间读取另一个流,拿到的数据也是完全一样的。不过由于另一个流没有被读取,克隆的数据可能会被浏览器放在一个缓冲区里,即便后续被读取可能也无法被浏览器即时 GC。123456789101112131415161718const file = document.querySelector('input[type="file"]').files[0];const stream = file.stream();const readStream = (stream) => {let total = 0;const reader = stream.getReader();const read = () => reader.read().then(({ value, done }) => {if (done) return;total += value.length;console.log(total);read();});read();};const [s1, s2] = stream.tee();readStream(s1);readStream(s2);例如在上述代码中选择一个 200MB 的文件,然后直接调用
readStream(stream),在 Chrome 浏览器下没有较大的内存起伏;如果调用stream.tee()后得到两个流s1和s2,如果同时对两个流调用readStream()方法,在 Chrome 浏览器下同样没有较大的内存起伏,最终输出的文件大小也是一致的;如果只对s1调用的话,会发现执行结束后 Chrome 浏览器下内存占用多了约 200MB,此时再对s2调用,最终得到的文件大小虽然一致,但是内存并没有及时被 GC 回收,此时浏览器的内存占用还是之前的 200MB。可能你会好奇,之前我们尝试过使用
tee()方法得到两段流,一个流直接返回另一个流用于输出下载进度,会有这样的资源占用问题吗?会不会出现两个流速度不一致的情况?其实计算下载进度的代码并不会非常耗时,数据计算完成后也不会再有多余的引用,浏览器可以迅速 GC。此外计算的速度是大于网络传输本身的速度的,所以并不会造成瓶颈,可以认为两个流最终的速度是基本一样的。 -
Q2. **如果不调用
controller.error()抛出错误强制中断流,而是继续之前的流程调用controller.close()关闭流,会发生什么事吗?从上面的结果来看,当我们调用
aborter()方法时,请求被成功中止了。不过如果不调用controller.error()这个方法抛出错误的话,由于我们主动关闭了 fetch 请求返回的流,循环调用的reader.read()方法会接收到done = true,然后会调用controller.close()。这就意味着这个流是被正常关闭的,此时 Promise 链的后续操作不会被中断,而是会收到已经传输的不完整数据。如果没有做特殊的逻辑处理的话,直接返回不完整的数据可能会导致错误。不过如果能好好利用上的话,或许可以做更多事情——比如断点续传的另一种实现,这就有点像 Firefox 的私有实现
moz-chunked-arraybuffer了。 -
Q3. **StreamSaver.js 在不支持
TransformStream的浏览器下其实是可以正常工作的,这是怎么实现的呢?记得我们之前提到过构造一个
ReadableSteam然后包装成Response对象返回的实现吧?我们最终的目的是需要构造一个流并返回给浏览器,这样传入的数据可以立即被下载,并且没有多余引用而迅速 GC。所以对于不支持TransformStream甚至WritableStream的浏览器,StreamSaver.js 封装了一个模拟WritableStream实现的 polyfill。当 polyfill 得到数据时,会将得到的数据片段通过MessageChannel直接传递给 Service Worker。Service Worker 发现这不是一个流,会构造出一个ReadableStream实例,并将数据通过controller.enqueue()方法传递进流。后续的流程估计你已经猜到了,和当前的后续流程是一样的,同样是生成一个随机 URL 并跳转,然后返回封装了这个流的Response对象。
参考资料
本文基于 CC BY-SA 4.0 协议 进行许可,使用本文请注明来源。